
آموزش کار با API ها در دیتابیس InfluxDB
در این آموزش، نحوه احراز هویت از طریق API، خواندن یک جریان داده، ذخیره آن به عنوان یک سری زمانی در InfluxDB و اجرای کوئری ها بر روی داده ها با استفاده از API InfluxDB را خواهید آموخت.
دیتابیس های سری زمانی (Time series) مانند InfluxDB، داده ها را بر اساس زمان فهرست بندی می کنند. داده ها در دیتابیس سری زمانی همیشه با جدیدترین مقدار نوشته می شوند اما همچنان داده های قدیمی هم نگه داشته می شوند.
در مدل قدیمی، برای ثبت اطلاعات جدید، اطلاعات قدیمی را باید تغییر دهید اما در پایگاه داده سری زمانی می توانید تمام داده ها را در طول زمان های مختلف ذخیره کنید.
Telegraf یک روش عالی برای جمع آوری داده ها برای InfluxDB است، اما در برخی موارد، ممکن است نیاز باشد از یک رابط اپلیکیشن (API) برای توسعه برنامه تان استفاده کنید. به عنوان مثال، اگر قبل از قرار دادن داده ها در دیتابیس سری زمانی خود، نیاز به پردازش اولیه دارید یا اگر یک پلاگین ورودی برای Telegraf سازگار با سیستم منبع خود پیدا نکردید، می توانید از API استفاده کنید.
قبل از شروع، باید InfluxDB 2.x را بر روی سیستم عامل خود به همراه یک کلاینت HTTP مانند curl، httpie یا Postman نصب کنید.
در این آموزش نحوه استفاده از یک نمونه InfluxDB محلی را در دستگاه تان به شما نشان می دهیم، اما همچنین می توانید از InfluxDB Cloud برای شروع سریعتر و بدون نیاز به نصب چیزی بر روی دستگاه خود استفاده کنید.
منظور از دیتابیس سری زمانی چیست؟
پایگاه داده سری زمانی دسته جدیدی از ذخایر داده های تخصصی است که به مدل های داده نیاز دارد که یک بُعد آن مبتنی بر زمان است.
چند مثال از این نوع داده ها عبارتند از:
- دما در یک نقطه جغرافیایی خاص در یک زمان معین از روز
- تعداد افرادی که از یک خیابان در ساعات شلوغی عبور می کنند
- یا تعداد ثبت نام در یک اپلیکیشن در طول هفته
داده های تجمعی با تعیین نقاط زمانی رخ دادن، داده هایی هستند که در پایگاه داده سری زمانی ذخیره می شوند.
در ادامه چند نمونه از داده های سری زمانی آورده شده است:
- داده حسگرها: دستگاه های کوچکی که می توانند اقدامات خاصی را ثبت کنند و منبع خوبی برای داده های سری زمانی هستند.
- داده های مالی: قیمت سهام یا ارزش دارایی های مالی در طول زمان تغییر می کند و نمونه ای کلاسیک از داده های سری زمانی را ارائه می دهد.
- داده های پایش زیرساخت محاسباتی: با رشد زیرساخت ابری، تعداد ابزارهای نظارتی نیز افزایش یافته که داده های زیادی از عملکرد هر قسمت جمع آوری می کند.
InfluxDB یکی از بهترین ابزارهایی است که می توانید از آن برای جمع آوری این نوع داده ها استفاده کنید، زیرا می توانید داده ها را به روشی سازگار و مقیاس پذیر جمع آوری، ذخیره و جستجو کنید.
InfluxDB API
InfluxDB API (در حال حاضر در نسخه 2.x) مجموعه ای از نقاط پایانی HTTP است که دسترسی برنامه ریزی شده به تمام عملکردهای سیستم InfluxDB را فراهم می کند. API توسط منابع و اقداماتی خاص بر روی این داده ها مستقر شده است.
نقاط پایانی شامل موارد زیر است:
- اطلاعات سیستم: نقاط پایانی می توانند وضعیت یک نمونه، آمادگی یک نمونه در هنگام راه اندازی، سلامت یک نمونه و مسیرهای سطح بالای موجود را بررسی کنند.
- امنیت و دسترسی: نقاط پایانی سازمان ها، کاربران و مجوزهایی را مدیریت می کنند که توکن هایی را برای دسترسی به API ارائه می کنند. این رویکرد امنیتی مبتنی بر توکن، توکن های مستقلی را فراهم می کند که به مدیران سازمان ها دسترسی و مجوز می دهد.
- دسترسی به منابع: نقاط پایانی می توانند bucketها، داشبوردها، وظایف و سایر منابع را مدیریت کنند.
- ورودی/خروجی داده: نقاط پایانی اقدامات خواندن و نوشتن را برای داده ها در یک bucket انجام می دهند.
- منابع دیگر: نقاط پایانی امکان اجرای عملیات پشتیبان گیری را می دهند و سایر منابع InfluxDB مانند Cells، Checks، Tags و Notification Rules را مدیریت کنید.
در این آموزش، از نقاط پایانی Data I/O برای نوشتن و کوئری کردن API استفاده می کنیم، اما قبل از شروع، باید روش های مختلف احراز هویتی را که می توانید برای فراخوانی نقاط پایانی InfluxDB API استفاده کنید، بشناسید.
بررسی پلن های پایگاه داده InfluxDB
انواع احراز هویت
سه روش احراز هویت برای استفاده در InfluxDB وجود دارد:
- _user/password_ combination که همچنین به عنوان _Basic Authentication_ شناخته می شود، که در آن یک رشته _user:password_ رمزگذاری شده ارسال می کنید.
- · _query string_ method از دو پارامتر رمزگذاری شده با URL (_u و p_) استفاده می کند.
- احراز هویت مبتنی بر توکن، که ترجیح داده می شود از این روش استفاده شود.
برای دو گزینه اول، باید یک نام کاربری و رمز عبور ایجاد کنید. اما در این آموزش، از احراز هویت مبتنی بر توکن استفاده می کنیم که می توانید از رابط کاربری InfluxDB استفاده یا نقطه پایانی /api/v2/authorizations API را ایجاد کنید.
برقراری ارتباط
استفاده از رویکرد مبتنی بر توکن به این دلیل اولویت دارد که روش های احراز هویت Basic و QueryString از طرح توکن پشتیبانی نمی کنند.
پس از نصب InfluxDB در زمان اجرا، از شما خواسته می شود که یک سازمان، کاربر و bucket ایجاد کنید.
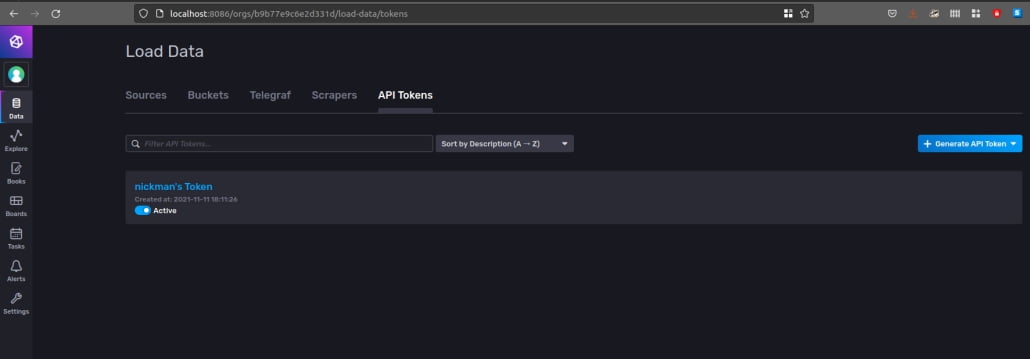
پس از ایجاد سازمان، کاربر و bucket، توکن APIای که به صورت خودکار ایجاد شده را در تب Load Data > API Tokens بررسی کنید.
در این رابط می توانید با انتخاب دکمه Generate API Token توکن های جدیدی ایجاد کنید. در آنجا همچنین می توانید توکن را نام گذاری و مجوزها را تعیین کنید.
برای این مثال، توکن استفاده شده دسترسی کامل و تمام مجوزها را دارد، اما در محیط های تولید باید کمترین دسترسی ها را اعمال کرد.
برای آزمایش وضعیت دسترسی خود به نمونه InfluxDB، از نقطه پایانی _/ping_ استفاده کنید. به عنوان مثال، از کلاینت _curl_ روی ترمینال زیر استفاده کنید:
$ curl localhost:8086/Health
یک پاسخ JSON دریافت می کنید که شامل وضعیت و نسخه سرور محلی است:
{
"checks": [],
"commit": "657e1839de",
"message": "ready for queries and writes",
"name": "influxdb",
"status": "pass",
"version": "2.1.1"
}فعال کردن رمزگذاری TLS/SSL
مانند هر منبع دیگری که برای دسترسی خارجی باز است، باید سعی کنید خطرات امنیتی احتمالی مانند افشای داده ها را حتی در یک محیط کنترل شده، به حداقل برسانید.
می توانید از SSL/TLS برای رمزگذاری ارتباط بین API و مصرف کنندگان، با دریافت گواهی و پیکربندی InfluxDB برای استفاده از گواهی به منظور رمزگذاری داده ها استفاده کنید.
می توانید دستورالعمل های امنیتی و مجوز influxdata را دنبال کنید تا رمزگذاری TLS/SSL را فعال کنید که به کلاینت ها امکان می دهد صحت سرور InfluxDB را تأیید کنند.
وارد کردن داده ها
برای وارد کردن داده ها با استفاده از API، به سازمان مقصد و bucket نیاز دارید. ما در این آموزش از دیتابیس حاوی داده های جهانی انتشار گاز CO2 استفاده خواهیم کرد. فایل را دانلود کنید و در همان پوشه ای که برای این آموزش استفاده می کنید ذخیره کنید. برای اسکریپت های زیر باید فایل CSV را در همان دایرکتوری قرار دهید.
بیایید از API برای بررسی تمام bucket های موجود که نقطه پایانی _/api/v2/buckets_ را فراخوانی می کنند، استفاده کنیم:
curl http://localhost:8086/api/v2/buckets –header “Authorization: Token your_api_token”
پاسخ JSON شامل حداقل سه bucket است. صفحه راه اندازی که بالاتر نشان دادیم، _InfluxDB-API-test-bucket_، صفحه ای است که در ابتدا پیکربندی شد و مقصد آزمایش ما بود.
{
"id": "81fef1d4510e235d",
"orgID": "b9b77e9c6e2d331d",
"type": "user",
"name": "InfluxDB-API-test-bucket",
"retentionRules": [
{
"type": "expire",
"everySeconds": 0,
"shardGroupDurationSeconds": 604800
}
],
"createdAt": "2021-11-11T23:11:26.588182068Z",
"updatedAt": "2021-11-11T23:11:26.588182158Z",
"links": {
"labels": "/api/v2/buckets/81fef1d4510e235d/labels",
"members": "/api/v2/buckets/81fef1d4510e235d/members",
"org": "/api/v2/orgs/b9b77e9c6e2d331d",
"owners": "/api/v2/buckets/81fef1d4510e235d/owners",
"self": "/api/v2/buckets/81fef1d4510e235d",
"write": "/api/v2/write?org=b9b77e9c6e2d331d\u0026bucket=81fef1d4510e235d"
},
"labels": []
}|مقدار orgID را برای استفاده به عنوان آرگومان در درخواست های زیر ذخیره کنید.
حالا، از یک مجموعه داده باز برای نوشتن داده ها در bucket استفاده کنید: انتشار جهانی CO2 از سوخت های فسیلی از سال 1751. این bucket حاوی 266 سال انتشار کربن است که توسط مرکز تجزیه و تحلیل اطلاعات دی اکسید کربن گردآوری شده. با یک اسکریپت ساده bash، می توانید فایل را بخوانید، جالبترین مقادیر هر سال را چاپ کنید و دادهها را در bucket InfluxDB بنویسید.
برای شروع، بیایید یک اسکریپت ساده bash write.sh ایجاد کنیم:
#! /bin/bash
#1. iterates over the global_emissions.csv file and reads each comma-separated column
while IFS="," read -r Year Total GasFuel LiquidFuel SolidFuel Cement GasFlaring PerCapita
do
echo "Year: $Year , total: $Total , Per capita $PerCapita"
#2. Converts the value of the year into a UNIX timestamp
ts=`date "+%s" -u -d "Dec 31 $Year 23:59:59"`
#3. Inserts the total value of co2 per year
curl -i -XPOST "http://localhost:8086/api/v2/write?precision=s&orgID=$1&bucket=$2" \
--header "Authorization: Token $3" \
--data-raw "total_co2,source=CDIAC value=$Total $ts"
#4. Checks if there is a value per capita
if [ -z "$PerCapita" ]; then
PerCapita=0
fi
#5. Inserts the per capita value of co2 emissions per year
curl -i -XPOST "http://localhost:8086/api/v2/write?precision=s&orgID=$1&bucket=$2" \
--header "Authorization: Token $3" \
--data-raw "per_capita_co2,source=CDIAC value=$PerCapita $ts"
done < <(tail -n +2 global_emissions.csv)اسکریپت بالا کارهای زیر را انجام می دهد:
- روی فایل global_emissions.csv تکرار می شود و هر ستون جدا شده با کاما را می خواند
- ارزش سال را به فرمت زمانی یونیکس تبدیل می کند
- مقدار کل CO2 در سال را درج می کند
- بررسی می کند که آیا ارزش سرانه وجود دارد یا خیر
- مقدار سرانه انتشار CO2 در سال را وارد می کند
می توانید با استفاده از ترمینال، این اسکریپت را فراخوانی کنید و سه آرگومان جدا شده با فاصله را ارسال کنید: شناسه سازمان (شناسه org که قبلاً ذخیره شده است)، نام bucket و توکن API که قبلاً استفاده شده بود.
توجه داشته باشید که اسکریپت قبلی به دنبال فایل global_emissions.csv در همان پوشه اسکریپت می گردد.
هنگامی که فایل منبع و اسکریپت را با هم دریافت کردید، می توانید آن را با این کار اجرا کنید:
./write.sh b9b77e9c6e2d331d InfluxDB-API-test-bucket your_api_token
خروجی باید شبیه کد زیر باشد، که یک کد پاسخ HTTP 204 در هر فراخوانی API است.
HTTP/1.1 204 No Content
X-Influxdb-Build: OSS
X-Influxdb-Version: 2.1.1
Date: Fri, 12 Nov 2021 00:05:44 GMTبه فراخوانی InfluxDB /api/v2/write endpoint توجه کنید. همانطور که ثبت شده، به پارامترهای دقیق، سازماندهی و کوئری bucket نیاز دارد و انتظار دارد که از پروتکل خط InfluxDB پیروی کند.
این پروتکل یک نمایش داده مبتنی بر متن است که شامل چهار جزء است:
- اندازه گیری: چیزی که اندازه می گیرید
- مجموعه تگ: چگونه اندازه گیری را شناسایی کنیم
- مجموعه فیلد: مجموعه ای از مقادیر مرتبط با اندازه گیری
- مهر زمانی: زمانی که آخرین اندازه گیری انجام شد
با استفاده از این فرمت می توانید داده های سری زمانی پیچیده را بیان کنید. در این مثال، تنها اندازه گیری کل CO2 و CO2 سرانه در bucket نوشته شده است.
جستجوی (کوئری) داده ها
مشابه عملیات نوشتن، یک نقطه پایانی query وجود دارد که یک کوئری در زبان Flux (که یک زبان مختصر و کاربردی است که برای کوئری، تجزیه و تحلیل و عمل بر روی داده ها طراحی شده است) را به عنوان بار می پذیرد. همچنین برای فراخوانی نقطه پایانی از مقدار orgID که قبلاً به عنوان پارامتر کوئری ذخیره شده است استفاده خواهید کرد.
سپس کوئری، یک نتیجه CSV با میانگین CO2 کل هر پنج سال، از سال 2000 تا 2015 را تولید می کند:
curl --request POST \
http://localhost:8086/api/v2/query?orgID=your_org_id \
--header 'Authorization: Token your_api_token' \
--header 'Accept: application/csv' \
--header 'Content-type: application/vnd.flux' \
--data 'from(bucket:"InfluxDB-API-test-bucket")
|> range(start: 2000-12-31T00:00:00Z, stop: 2015-01-01T00:00:00Z)
|> filter(fn: (r) => r._measurement == "total_co2")
|> aggregateWindow(every: 5y, fn: mean)'کوئری /api/v2/ می تواند نتایج را با استفاده از یک هدر اضافی در درخواست فشرده کند.
همچنین می توانید مجموعهای از جفت های key/value را در آن قرار دهید که نشان دهنده پارامترهایی است که باید به کوئری تزریق شوند یا حتی نتایج را به عنوان یک زبان CSV خاص دریافت کنید. این امر استخراج داده ها را به یک کار ساده تبدیل می کند.
اگر پایگاه داده InfluxDB v1.x دارید، می توانید با استفاده از InfluxDB v2.x API نیز داده های خود را جستجو کنید. ابتدا بررسی کنید که پایگاه داده و خط سیاست حفظ با استفاده از /api/v2/dbrps نقاط پایانی به یک bucket ثبت شده اند تا ثبت های لازم را فهرست و ایجاد کنید و سپس کوئری را با استفاده از API اجرا کنید:
curl --request GET \
http://localhost:8086/api/v2/query?orgID=your_org_id \
--header 'Authorization: Token your_token' \
--header 'Accept: application/csv' \
--header 'Content-type: application/json' \
--data-urlencode "q=SELECT mean(*) FROM example-db.example-rp.total_co2"با توجه به اینکه این آموزش از پایگاه داده InfluxDB v2.x استفاده می کند، نمی توانید این نمونه InfluxQL را مستقیماً با تنظیمات فعلی آزمایش کنید. اما برای تست سازگاری با نسخه های قبلی مفید است.
یک اشتباه رایجی که ممکن است در یک پایگاه داده سری زمانی مانند InfluxDB با آن مواجه شوید این است که سعی کنید راه حل خود را بر اساس پارادایم رابطه ای طراحی کنید. مستندات InfluxDB بهترین روش ها را برای طراحی اسکیما در موارد استفاده سری زمانی ارائه می کند که باید قبل از شروع مدل سازی مرور کنید.
نتیجه
در این آموزش، یاد گرفتید که اصول استفاده از InfluxDB HTTP API چیست، چگونه می توانید اعتبار API را در یک نمونه InfluxDB تأیید و آزمایش کنید و چگونه از نقطه پایانی نوشتن برای ارسال داده با استفاده از line protocol استفاده کنید.
همچنین نحوه خواندن داده ها را با استفاده از زبان Flux آموختید. اسکریپت و داده های مورد استفاده به عنوان GitHub Gist در دسترس هستند.
InfluxDB HTTP API منابع و اقدامات زیادی را در اختیار شما قرار می دهد که می توان از آنها به روش برنامه نویسی استفاده کرد و انعطاف پذیری و سازگاری را با هر زبان برنامه نویسی اضافه کرد. می توانید با استفاده از هر یک از روش های نصب InfluxDB، API HTTP InfluxDB را به صورت محلی اجرا کنید، یا می توانید پلتفرم InfluxData را امتحان کنید تا از تمام امکانات یک محیط مدیریت شده استفاده کنید.
به یاد داشته باشید که می توانید از کلاینت های API موجود برای بسیاری از زبان های محبوب نیز استفاده کنید.





دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.