
پایگاه داده گراف یا Graph DataBase چیست و چه تفاوتی با سایر دیتابیس ها دارد؟
به عنوان یک توسعه دهنده یا تحلیل گر پایگاه داده ممکن است نام پایگاه داده گراف را شنیده باشید، اما شاید از چگونگی کار آن اطلاع دقیقی نداشته باشید. در این مقاله در رابطه با پایگاه داده گراف (Graph Database) و موارد استفاده از آن و همچنین مزیت های این پایگاه داده می خوانید.
پایگاه داده گراف چیست؟
به زبان ساده می توان گفت پایگاه داده گراف یا Graph DataBase به گونه ای طراحی شده است که ارتباطات بین داده ها به اندازه خود داده ها مهم در نظر گرفته شود. همچنین داده ها را به گونه ای انعطاف پذیر ذخیره می کند که محدود به یک مدل موجود نباشد. در این پایگاه داده، داده ها نگهداری شده و همانند آنچه روی یک تخته مشاهده می شود، به وضوح هر مقدار و نحوه اتصال آن به مقدار دیگر مشخص است.
همانند هر سیستم پایگاه داده دیگری، پایگاه داده گراف ذخیره سازی و بازیابی کارآمد داده ها برای کاربردهای مختلف را ممکن می سازد. مانند پایگاه داده RDBMS که از قدیمی ترین و محبوب ترین پایگاه های داده محسوب می شود، پایگاه داده گراف نیز برای سازماندهی مداوم و سیستماتیک داده ها با هدف پشتیبانی از سوالات (questions)، domain-specific knowledge و unique applications که در هسته اصلی هر سازمان وجود دارد، قابل استفاده است. با این وجود، نحوه ذخیره سازی و بازیابی داده ها است که اساسا پایگاه داده گراف را از سایر سیستم های سنتی مانند RDBMS که مبتنی بر SQL است، متمایز می کند. بررسی این تفاوت ها مشخص می کند که دقیقا چه مواردی باعث تمایز این پایگاه داده (که از گزینه های ذخیره سازی داده ها است) از سایر دیتابیس ها می شود.
چرا پایگاه داده گراف؟
اساسی ترین جنبه یک پایگاه داده گراف، نوع ساختار داده ای است که از آن برای ذخیره سازی داده ها استفاده می کند، که گراف نامیده می شود.
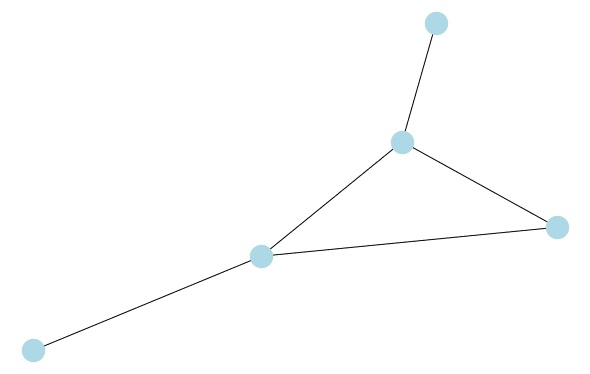
گراف ها متشکل از مجموعه ای از گره ها هستند که توسط یال ها یا روابط به هم متصل شده اند. گراف ها ساختار پایه ای علوم کامپیوتر و ریاضیات به شمار می روند، دلیل این امر نیز توانایی آن ها در توصیف بهینه تر پیچیدگی اتصالات طبیعی در جهان است. از آنجا که نمودارها مانند مغز انسان، با اتصال مفاهیم به یکدیگر از طریق روابط بین آن ها؛ داده ها را ذخیره می کنند، در نتیجه این روش، روش شهودی تری برای ذخیره، تجزیه و تحلیل و درک داده ها ارائه می دهد.
جای تعجب نیست که این ارتباطات طبیعی ارزشمند در همه بخش های داده های ما وجود داشته باشد. با در نظر گرفتن این واقعیت، وجود یک پایگاه داده بومی که این ارتباطات ذاتی را در داده های ما در نظر گیرد، ضروری است. پایگاه داده گراف می تواند داده های ما را در مقیاس های مختلف، با تمرکز ویژه بر حفظ اطلاعات و الگوهای منحصر به فرد و با ارزش و همچنین حفظ ارتباطات بین آن ها، ذخیره کند.
برای فهم بیشتر این موضوع مثالی ساده را بیان می کنیم.
تفاوت یک Graph DataBase با سایر دیتابیس ها در چیست؟
مجموعه داده سنتی جدولی زیر را در نظر بگیرید:

برای رسیدن به هدف ساده نگهداری سوابق و جستجو در آن ها، این ساختار جدولی حاوی سطر و ستون به خوبی کار می کند ( همانطور که در پایگاه های داده کلاسیک RDBMS مانند Microsoft SQL Server و MySQL استفاده می شود). رسیدن به پاسخ سوالی مانند اینکه “Sonya کجا زندگی می کند؟” بسیار ساده است. با جستجو در رکورد مربوط به Sonya و رسیدن به ستون آدرس می توان به پاسخ مد نظر رسید. اما در صورتی که سوال ذاتا مرتبط تری مانند ” چه فرد دیگری در آدرس Sonya زندگی می کند؟” بپرسیم، با استفاده از این قالب سنتی جدولی، در پاسخ به این گونه سوالات با چالش مواجه می شویم.
برای اینکه با استفاده از همین ساختار داده جدولی به این سوال پاسخ دهیم، ابتدا باید مانند قبل در رکورد Sonya جستجو کنیم و آدرس آن را پیدا کنیم و سپس یک جستجوی دیگر بر اساس آدرس پیدا شده انجام دهیم تا به پاسخ درست برسیم. در چنین ساختار ساده ای هم این یک مرحله اضافی به شمار می رود، چه برسد به پیچیدگی و منابع محاسباتی بالایی که در مقیاس سازمانی باید صرف چنین سوالات به هم پیوسته ای شود. از این رو این روش قابل دفاع در سطح سازمانی نخواهد بود.
مثال هایی از پایگاه داده گراف
اگر از منظر یک نمودار به این موضوع نگاه کنیم، برای یافتن ساختار داده ها به عنوان یک نمودار، به سادگی تمام موجودیت های متمایز در داده ها را استخراج می کنیم و آن ها را به عنوان گره ها در نظر می گیریم:
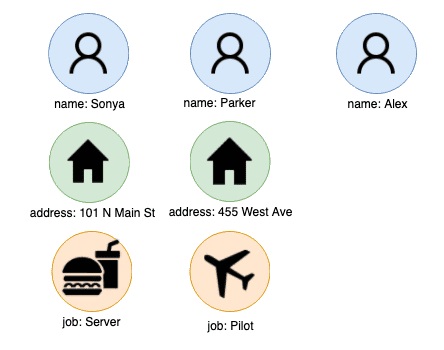
در برخی موارد این کار به سادگی جمع آوری مقادیر منحصر به فرد از هر ستون از داده ها است. با این حال برای داده های ساختار یافته تر مانند ردیف آدرس ها، ایمیل ها و یا نام شرکت ها، در این فرآیند به پردازش های بیشتری نیاز است تا موجودیت ها تحلیل شود. این مرحله اغلب اولین چیزی است که کاربران هنگام استفاده از پایگاه داده گراف با آن مواجه می شوند.
بدین ترتیب با استفاده از تکنیک های مدرن پردازش زبان طبیعی (NLP)، می توان مقدار انبوهی از داده های ساختار نیافته un-leveraged سازمان ها را، از طریق پایگاه داده گراف که روشی مقیاس پذیر، مناسب و منحصر به فرد برای هدایت این داده ها است، ذخیره کرد. از جمله این داده های انبوه می توان به نظرات مشتریان در رسانه های اجتماعی، مستندات محصولات، فهرست ها، پایگاه های دانش و بسیاری دیگر اشاره کرد که دارای ماهیت های بسیار مرتبط هستند.
پس از استخراج موجودیت های منحصر به فرد از داده ها در قالب گره ها، با تعیین نوع رابطه بین این گره ها، یال ها یا روابط را بین گره هایی که با یکدیگر دارای اشتراک هستند برقرار می کنیم. در نتیجه با این کار نه تنها واقعیت مرتبط بودن دو گره ذخیره می شود، بلکه نحوه مرتبط بودن آن دو گره نیز ذخیره خواهد شد که ماهیت اتصال داده ها را بیشتر به تصویر می کشد و ما را قادر می سازد تا به سوال دشواری که قبلا چالش برانگیز بود به خوبی پاسخ دهیم.
با توجه به ساختار جدیدی که داده ها دارند و به صورت نمودار در آن ذخیره شده اند، به راحتی می توان به سوال ” چه فرد دیگری در آدرس Sonya زندگی می کند؟” پاسخ داد. با جستجوی گره ای که مربوط به Sonya است، رکورد مورد نظر را تعیین می کنیم.
پس از تعیین مکان گره مورد نظر، یافتن رکورد آدرس به سادگی پیمایش از طریق رابطه یا یال HAS_ADDRESS است:
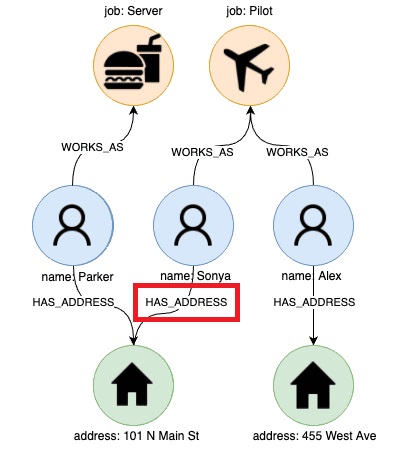
برای رسیدن به پاسخ نهایی تنها باید تمام روابط HAS_ADDRESS دیگر را که به گره آدرس متصل هستند، دنبال کنیم. در نتیجه بدون نیاز به جستجوی اضافی در همه گره های مجاور، تنها در گره های مرتبط جستجو انجام می شود و پیچیدگی و زمان جستجو را بسیار کاهش می دهد.
با استفاده از این ماهیت ارتباطی گراف مانند در پایگاه داده، ما می توانیم به جای پرسیدن سوال و رسیدن به پاسخ از طریق یک سری جستجوهای SQL پیچیده و هزینه بر، در بین سطر ها و ستونهایی که به این صورت ذخیره شده اند، طعم یک زبان کوئری گراف (مثلاً Cypher یا Gremlin) را در میان داده هایی که در مجاورت آن ها هستند بچشیم و این روش یک راه جایگزین پر سرعت برای رسیدن به پاسخ سوالات پیچیده مرتبط، به شمار می رود.
با اینکه گراف و تئوری گراف سال هاست که در ریاضیات و علوم کامپیوتر، برای حل تعدادی از سوالات مرتبط به هم مانند این، مورد استفاده قرار گرفته است، تنها در چند سال اخیر است که شاهد استفاده از این ساختار داده قدرتمند به عنوان ستون اصلی ذخیره سازی داده ها بوده ایم. پایگاه داده ای که اکنون به عنوان یک ذخیره ساز مقیاس پذیر برای بازیابی داده های به هم پیوسته در کسب و کار ها به کار گرفته می شود.
معروف ترین پایگاه داده های گرافی
- Neo4J : از جمله معروف ترین پایگاه داده گرافی است که برای رایانش ابری (که در پایگاه داده ابری اجرا می شود) مناسب است.
- AllegroGraph
- ArangoDB: یکی از ویژگی های اصلی این پایگاه داده گرافی انعطاف پذیری در مدل سازی داده ها است.
- InfinitGraph
- OrientDB : این پایگاه داده گرافی هم از حالت Document-based و هم گرافی پشتیبانی می کند.
- Titan: از پایگاه داده های گرافی است که برای پردازش میلیارد ها گره و یال در بین چند دستگاه را دارد.
- StartDog
- MarkLogic
پیش بینی آینده گراف ها
گارتنر پیش بینی کرده بود پایگاه داده های گراف سالانه 100 درصد رشد خواهند داشت و این گراف ها پایه و اساس قابلیت های مدرن در تجزیه و تحلیل داده ها را شکل خواهند داد. این روند به سرعت در حال پیشرفت است، زیرا سازمان ها به دنبال استفاده موثر تر از داده های خود و ایجاد یک تمایز رقابتی به روش هایی هستند، که تا قبل از این ممکن نبوده است.
انتظار میرود پایگاههای داده گراف نقش مهمی در حوزههای متنوعی مانند یادگیری ماشین، تحلیل بیزی، علم داده و هوش مصنوعی و همچنین کمک به مدیریت دادههای سازمانی و تبادل دادهها در دهه های آینده ایفا کنند.
یکی از مهمترین تاثیرات روی این نوع پایگاهداده، بهبود در federation دادهها خواهد بود. زمانی که نمودارهای دانش را بتوان به راحتی ترکیب کرد، پایگاه داده ها میتوانند تعیین کنند که اگر به دادههایی نیاز دارند، که در حال حاضر آن ها را ندارد، به طور خودکار آن دادهها را از سایر گراف های دانش بازیابی کند. با این توانایی، این احتمال وجود دارد که federation به توسعه دهندگان کمک کند تا بلاک چین هایی ایجاد کنند که از ابرداده های مربوطه برای احراز هویت تراکنش های بانکی، مالی، رای گیری و قراردادهای هوشمند استفاده کنند.

چه زمانی به پایگاه داده گراف نیاز داریم؟
- زمانی که پایگاه داده گراف مشکلات رابطه چندگانه(Many-To-Many relationship) را حل می کند.
- زمانی که روابط بین داده ها بسیار مهم است.
- زمانی که در داده های بزرگ، زمان تاخیر در پاسخگویی به جستجو ها باید بسیار کم باشد.
مزایا و محدودیت های پایگاه داده گراف
از مزایای این پایگاه داده می توان به تغییرات مکرر طرحواره یا اسکیما (Frequent schema changes)، مدیریت حجم بالایی از داده ها (managing volume of data)، پاسخگویی در لحظه (real-time query response time) و فعالسازی هوشمند داده ها (intelligent data activation requirements) را نام برد. اما باید توجه داشت که پایگاه داده گراف همیشه بهترین راه حل نیست و باید قبل از تصمیم گیری در استفاده از این معماری، نیاز ها را سنجید و سپس تصمیم گیری نمود.
از محدودیت های این پایگاه داده به موارد زیر می توان اشاره کرد:
- پایگاه داده گراف در داده های NoSQL انتخاب خوبی نخواهد بود.
- اگر برنامه نیاز به مقیاس افقی داشته باشد، عملکرد ضعیفی خواهد داشت.
- هنگام به روز رسانی تمام گره ها با یک پارامتر داده شده، کارآمد نیست.
نتیجه گیری
نکته قابل توجه در انتخاب دیتابیس مناسب برای سازمان ها این است که در ابتدا باید نیازسنجی ها به درستی صورت گیرد تا بتوان از بین انواع مختلف پایگاه داده، مناسب ترین نوع آن را انتخاب کرد. همانطور که خواندید پایگاه داده گراف یکی از انواع پایگاه داده های دارای معماری گرافی است که در موارد خاص بسیار پرکاربرد است. با استفاده از این پایگاه داده به راحتی می توان داده ها و روابط بین آن ها را در قالب گره ها و یال ها که ارتباط دهنده گره ها هستند، ذخیره کرد و هر زمان که نیاز بود به آسانی به آن ها دسترسی داشت. با گذشت زمان استفاده از این نوع پایگاه داده بسیار بیشتر شده است. در آینده نیز کاربردهای بسیاری را در زمینه های مختلف از جمله هوش مصنوعی خواهد داشت.










دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.