آشنایی با بحث شاردینگ در پایگاه داده یا همان Database Sharding
هر برنامه و یا وب سایتی که رشد قابل توجهی داشته باشد، برای مدیریت هرچه بهتر ترافیک خود، نیاز به مقیاس بندی خواهد داشت. برای برنامه ها و وب سایت های مبتنی بر داده بسیار مهم است که مقیاس بندی به شیوه ای انجام شود که امنیت و یکپارچگی داده های آن ها تضمین گردد. پیش بینی این نکته که وب سایت و یا برنامه های مختلف تا چه زمان محبوبیت خود را حفظ می کند، دشوار به نظر می رسد. از این رو برخی از سازمان ها و شرکت های مختلف معماری پایگاه داده ای خود را به نحوی انتخاب می کنند که به آن ها اجازه اجرای پایگاه داده به صورت پویا را خواهد داد. اینجاست که موضوع شاردینگ در پایگاه داده یا همان Database Sharding به میان می آید.
ما در این مطلب قصد داریم تا در خصوص یکی از معماری های مهم پایگاه داده، یعنی Database Sharding صحبت کنیم. مبحث Database Sharding در کنار مبحث دیتابیس ابری، توجهات زیادی را به خود اختصاص داده اند. اما هنوز هم بسیاری از افراد درک روشنی از چیستی آن و یا سناریوهایی که شاردینگ یک پایگاه داده دارد، ندارند. ما در ادامه در خصوص چیستی Database Sharding، برخی از مزایا و معایب اصلی آن و همچنین چند روش متداول Database Sharding صحبت خواهیم کرد.
شاردینگ یا Database Sharding چیست؟
شاردینگ و یا همان Database Sharding، یک الگوی معماری پایگاه داده بوده که با پارتیشن بندی افقی مرتبط است. این مفهوم همچنین به عنوان جداسازی ردیف های یک جدول به چندین جدول مختلف که به عنوان پارتیشن شناخته می شوند، شهرت دارد. هر پارتیشن دارای طرح و ستون های یکسان است. اما همین پارتیشن ها، دارای ردیف های کاملا متفاوتی هستند. به همین ترتیب، داده های نگهداری شده در هر پارتیشن، منحصر به فرد و مستقل از داده های نگهداری شده در هر پارتیشن دیگری است.
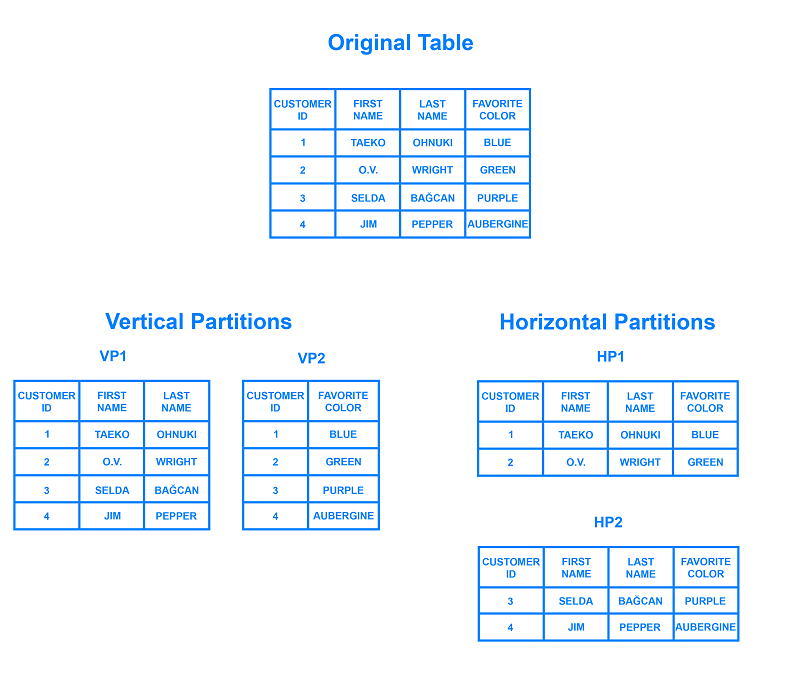
تفکر در خصوص پارتیشن بندی افقی از نظر ارتباط آن با پارتیشن بندی عمودی می تواند در بحث پایگاه داده بسیار مفید واقع شود. در یک جدول عمودی پارتیشن بندی شده، کل ستون ها جدا شده و در جداول جدید و مجزایی قرار می گیرند. داده هایی که در یک پارتیشن عمودی نگهداری می شوند، مستقل از داده های سایر پارتیشن ها هستند. هر کدام از آن ها نیز دارای ردیف ها و ستون های مجزا بوده که در دل خود جای داده اند. به کمک نمودار زیر می توانید بهتر متوجه شوید که چگونه می توان یک جدول را به صورت افقی و عمودی پارتیشن بندی کرد.
مبحث Database Sharding شامل تقسیم کردن داده ها به دو یا چند تکه کوچکتر است که به آن ها خرده های منطقی یا logical shards می گویند. سپس همین خرده های منطقی در میان گره های پایگاه داده جداگانه توزیع شده که به آن ها خرده های فیزیکی یا physical shards گفته می شود. هر یک خرده فیزیکی می تواند چندین خرده منطقی را در خود نگه دارد. با وجود این، داده هایی که در تمام خرده ها نگهداری می شوند، به طور جمعی یک مجموعه داده منطقی را نشان می دهند.
خرده های پایگاه داده یا Database Shards نمونه ای از یک معماری هیچ-اشتراک یا hared-nothing architecture هستند. این امر بدان معناست که هر کدام از خرده ها از دیگری مستقل است. آن ها هیچ یک از داده ها یا منابع محاسباتی یکسانی را به اشتراک نخواهند گذاشت. با این حال در برخی از موارد، ممکن است جداول خاصی را در هر شارد تکثیر کنیم تا به عنوان جدول مرجع از آن استفاده شود. به عنوان مثال تصور کنید یک پایگاه داده برای یک برنامه اپلیکیشن وجود دارد که به نرخ ثابت برای اندازه گیری وزن بستگی دارد. با تکثیر جدولی حاوی داده های نرخ تبدیل لازم در هر خرده یا شارد، می توان مطمئن شد که تمامی داده های مورد نیاز برای کوئری ها، در هر شارد نگهداری می شوند.
در برخی از اوقات sharding یا عملیات خرده شدن در سطح اپلیکیشن و برنامه اجرا می شود. به این معنی که اپلیکیشن شامل قطعه کدی است که مشخص می کند خواندن و نوشتن به کدام قطعه ارسال شود. با این وجود، برخی از سیستم های مدیریت پایگاه داده دارای قابلیت های sharding داخلی بوده که به شما این امکان را می دهد تا sharding را مستقیما در سطح پایگاه داده پیاده سازی کنید. حال که با نمای کلی مبحث Database Sharding آشنا شدید، بیایید با هم نگاهی به برخی از مهمترین مزایا و معایب این نوع از معماری پایگاه داده بیندازیم.
مزایای Database Sharding
جذابیت اصلی Database Sharding در یک پایگاه داده این است که می تواند به تسهیل شدن مقیاس بندی افقی، کمک کند. مقیاس بندی افقی عملی است برای افزودن ماشین های بیشتر به یک پشته موجود، به منظور پخش بار و تحمل ترافیک بیشتر و پردازش سریع تر. این امر در بیشتر مواقع با مقیاس بندی عمودی که به عنوان واحد افزایش مقیاس نیز شناخته می شود، در تضاد است. دلیل آن هم این نکته است که مقیاس بندی افقی بیشتر شامل ارتقا سخت افزار یک سرور موجود، مانند افزودن RAM یا CPU است.
وجود یک پایگاه داده رابطه ای که روی یک ماشین اجرا شده و یا ارتقا منابع محاسباتی در صورت لزوم، ساده خواهد بود. با اینکه همه پایگاه های داده غیر توزیع شده از نظر ذخیره سازی و قدرت محاسباتی محدود هستند، اما داشتن آزادی در مقیاس بندی افقی تنظیمات، می تواند باعث افزایش انعطاف پذیری شود.
دلیل دیگری که باعث شده تا معماری Database Sharding تا به این اندازه محبوبیت پیدا کند، سرعت بخشیدن به زمان اجرای کوئری ها است. زمانی که یک کوئری را در پایگاه داده ای که شارد نشده، ارسال می کنید، ممکن است نیاز باشد تا تمام ردیف های جدولی را که پرس و جو می کنید، مورد جستجو قرار دهید. تا بدین صورت به نتایج مورد نظر خود رسیده و آن را پیدا کنید. برای یک اپلیکیشن با پایگاه داده بزرگ و یکپارچه، کوئری ها می توانند به شدت کند باشند و روی عملکرد برنامه تاثیر گذار باشند. به همین دلیل با تقسیم کردن یک جدول به چند جدول، پرس و جوها باید از ردیف های کمتری عبور کرده و مجموعه نتایج آن ها با سرعت بیشتری بازگردانده می شود.
Database Sharding همچنین می تواند با کاهش تاثیر قطع شدن ها، به قابلیت اعتماد برنامه ها کمک کنند. اگر اپلیکیشن و یا وب سایت شما به یک پایگاه داده غیر شارد شده متکی است، این امکان وجود دارد که قطع شدن ارتباط با پایگاه داده، باعث گردد تا کل برنامه از دسترس خارج شود. با این حال در یک پایگاه داده شارد شده، قطع شدن ممکن است تنها بر یک قسمت از کل تاثیر بگذارد. با این که در این حالت نیز بخش هایی از اپلیکیشن و یا وب سایت از دسترس کاربران خارج می شود، اما تاثیر کلی آن از قطع شدن کل پایگاه داده بسیار کمتر است.
معایب Database Sharding
با اینکه شاردینگ یک پایگاه داده می تواند مقیاس پذیری آن را ساده تر کرده و عملکرد را بهبود ببخشد، اما قادر است تا محدودیت های خاصی را هم اعمال کند. در این بخش برخی از مهمترین دلایلی که چرا افراد از Database Sharding در معماری پایگاه داده خود استفاده نمی کنند را نام می بریم.
پیچیدگی بالا
اولین مشکلی که افراد با موضوع Database Sharding دارند، پیچیدگی بسیار زیاد آن در زمان اجرای معماری پایگاه داده است. در صورتی که این کار را اشتباه انجام دهید، خطرات بسیار زیادی وجود دارد که قادر است تا فرایند شاردینگ را مختل کرده و در نهایت به از دست رفتن داده ها و خراب شدن جداول بیانجامد. اما از سوی دیگر، اگر به درستی انجام شود، شاردینگ احتمالا تاثیر زیادی بر جریان کاری تیم شما خواهد داشت. به جای دسترسی و مدیریت داده های خود از یک نقطه ورودی، کاربران باید داده ها را در چندین مکان خرد شده مدیریت کنند. این امر قادر است تا به صورت بالقوه مشکلاتی را برای تیم ها ایجاد کند.
نامتعادل شدن شاردها
یکی از مشکلاتی که کاربران گاهی پس از Database Sharding با آن مواجه می شوند، این است که شاردها در نهایت نامتعادل می شوند. به عنوان مثال، فرض کنید که شما یک پایگاه داده با دو خرده، گره و یا شارد جداگانه دارید. یکی برای مشتریانی که نام خانوادگی آن ها از حرف a تا m است و دیگری برای کسانی که نامشان با حروف n تا z شروع می شود. حال تصور کنید که تعداد افرادی که نام خانوادگی آن ها با G آغاز می شود، بسیار زیاد باشد.
در این حالت قطعه A-M به تدریج داده های بیشتری را نسبت به N-Z جمع آوری می کند. همین امر موجب شده تا برنامه برای بخش قابل توجهی از کاربران کند شده و از کار بیفتد. شارد A-M در این حالت به چیزی بدل شده که به آن در پایگاه داده، هات اسپات گفته می شود. در این حالت تمامی مزایای Database Sharding به دلیل کاهش سرعت از بین خواهد رفت. پایگاه داده نیز به احتمال زیاد به تعمیر و اصلاح مجدد نیاز دارد تا مجددا امکان توریع یکنواخت داده را فراهم کند.
بازگردانی سخت
از دیگر مشکلاتی که بحث Database Sharding در پایگاه داده به وجود می آورد، بازگرداندن سخت آن به معماری unsharded است. پشتیبان گیری هایی که از پایگاه داده، قبل از تقسیم بندی انجام شده است، شامل داده های نوشته شده از زمان پارتیشن بندی نخواهد بود. در نتیجه بازسازی معماری اولیه بدون شکست، مستلزم ادغام داده های پارتیشن بندی شده جدید با نسخه های پشتیبان قدیمی یا تبدیل مجدد پایگاه داده پارتیشن شده به یک پایگاه داده واحد است که در هر دو حالت نیاز به هزینه و تلاش بسیار زیادی خواهد بود.
پشتیبانی نشدن توسط موتورهای پایگاه داده
نقطه ضعف دیگری که می توان برای Database Sharding به شمار آورد این است که شاردینگ به صورت بومی توسط موتورهای پایگاه داده پشتیبانی نمی شود. به عنوان مثال، PostgreSQL شاردینگ خودکار را به عنوان یک ویژگی شامل نخواهد شد. البته امکان تقسیم بندی پایگاه داده PostgreSQL به صورت دستی وجود دارد. تعدادی فورک PostgreSQL وجود داشته که شامل شاردینگ خودکار هستند، اما این فورک ها بیشتر بعد از آخرین نسخه PostgreSQL ارائه شده که فاقد ویژگی های دیگر هستند.
از سوی دیگر برخی از فناوری های پایگاه داده تخصصی مانند MySQL Cluster یا برخی از محصولات “پایگاه داده به عنوان سرویس”(DBaaS) مانند MongoDB Atlas شامل شاردنیگ خودکار به عنوان یک ویژگی هستند. اما نسخه های مختلف این سیستم های مدیریت پایگاه داده این گونه نیستند. به همین دلیل Database Sharding اغلب باعث دشوار شدن یافتن اسناد مربوط به شاردینگ و یا نکاتی برای عیب یابی خواهد شد.
آشنایی با برخی از معماری های شاردینگ
زمانی که تصمیم گرفتید تا پایگاه داده خود را شاردینگ کنید، باید بدانید که چگونه می توانید این کار را انجام دهید. هنگام اجرای کوئری ها یا توزیع داده های دریافتی در جداول پایگاه داده شارد شده، مهم است که قطعه کد به صورت صحیح کار کند. در غیر این صورت ممکن است در نهایت منجر به از دست رفتن داده ها یا کوئری های مخاطره آمیز شود. در این بخش قصد داریم تا برخی از رایج ترین معماری های Database Sharding را به شما معرفی کنیم.
1. شاردینگ مبتنی بر کلید (Key Based Sharding)
شاردینگ مبتنی بر کلید که به عنوان شاردینگ مبتنی بر هش (hash) نیز شناخته می شود، شامل استفاده از یک مقدار گرفته شده از داده های تازه نوشته شده (مانند شماره شناسه مشتری، آدرس IP برنامه مشتری، کد پستی و …) و اتصال آن به یک تابع درهم سازی (hash function) برای تعیین این نکته است که هر داده باید به کدام سمت و یا قطعه برود. تابع هش تابعی است که بخشی از داده (برای مثال ایمیل مشتری) را به عنوان ورودی گرفته و یک مقدار گسسته به نام مقدار هش را در خروجی نشان می دهد. در مورد شاردینگ، مقدار هش، یک شناسه شارد شده ای است که برای تعیین آن که داده های دریافتی در کدام قطعه ذخیره می شوند، استفاده می گردد. برای درک بیشتر به شکل زیر توجه کنید:
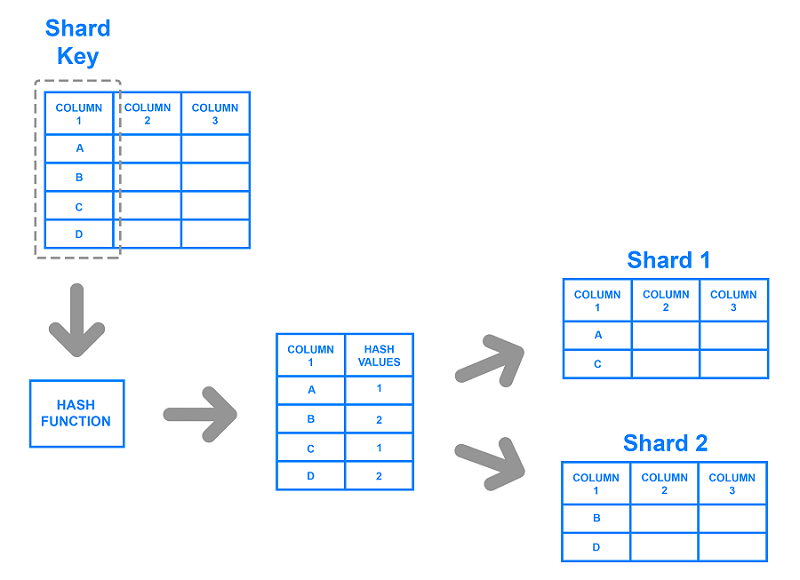
با اینکه Database Sharding مبتنی بر کلید یک معماری شاردینگ نسبتا رایج است، با این وجود زمان تلاش برای اضافه کردن و یا حذف سرورهای اضافی به پایگاه داده می تواند مشکل ساز باشد. همانطور که در حال اضافه کردن سرورها هستید، نیاز است تا مقدار هش مربوطه نیز اضافه شود. از این رو شاید نه همه اما بسیاری از ورودی های شما به مقدار هش جدید نیاز داشته و باید به سرور مناسب متنقل شوند. با شروع تعادل جدید داده ها، توابع هش قدیمی و همچنین توابع هش جدید، معتبر نخواهند بود. در نتیجه سرور شما نمی تواند در طول انتقال، داده های جدیدی را بنویسد و برنامه شما ممکن است در آستانه معیوب شدن قرار بگیرد. اما شاید مهمترین مزیت این معماری آن است که می توان از آن برای توزیع یکنواخت داده ها به منظور جلوگیری از هات اسپات، استفاده کرد. همچنین از آن جایی که داده ها به صورت الگوریتمی توزیع می شوند، نیازی به حفظ نقشه ای که نشان دهنده جایی که همه داده ها در آن قرار داند، وجود ندارد.
2. شاردینگ مبتنی بر محدوده (Range Based Sharding)
شاردینگ مبتنی بر محدوده شامل شاردینگ داده ها بر اساس محدوده های یک مقدار معین است. برای درک بهتر، فرض کنید که شما یک پایگاه داده دارید که اطلاعات مربوط به تمام محصولات را در کاتالوگ یک شارد فروش ذخیره می کند. شما می توانید چند قطعه مختلف ایجاد کرده و اطلاعات هر محصول را بر اساس محدوده قیمتی که در آن قرار می گیرد، تقسیم کنید. برای مثال به شکل زیر توجه کنید:
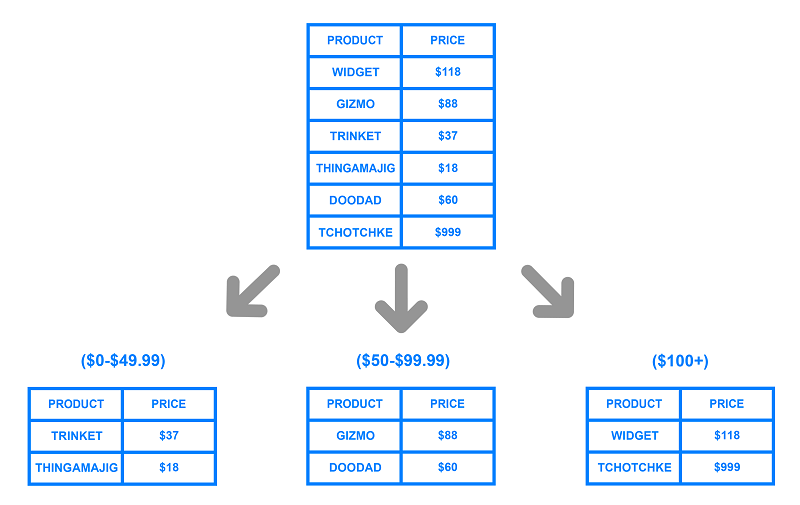
مهمترین مزیت Database Sharding مبتنی بر محدوده آن است که اجرای آن نسبتا آسان خواهد بود. هر شارد مجموعه ای متفاوت از داده ها را در خود جای می دهد. اما همه آن ها دارای طرحواره ای مشابه با یکدیگر و همچنین پایگاه داده اصلی خود هستند. کد برنامه می تواند مشخص کند که داده در کدام محدوده قرار گرفته و آن را در قطعه مربوطه وارد می کند.
از سوی دیگر، شاردینگ مبتنی بر محدوده، داده ها را از توزیع نابرابر محافظت نمی کند. همین امر منجر به ایجاد مشکل در پایگاه داده خواهد شد. با نگاهی به مثال بالا، می توان متوجه شد با این که هر شارد مقدار یکسانی از داده ها را در خود داشته، اما این احتمال وجود دارد که محصولات خاصی بیشتر مورد توجه قرار بگیرند.




دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.