افزایش کارایی خواندن از دیتابیس های postgres
امروزه PostgreSQL سریع ترین نرم افزار مدیریت دیتابیس در دنیا است با این وجود توسعه دهنده گان هنوز ترجیح میدهند از یک سیستم Non-relational استفاده کنند؛ فقط و فقط به خاطر یک مسئله: مقیاس گذاری
تفکری که حول PostgreSQL وجود دارد به این صورت است: PostgreSQL یک دیتابیس رابطهای است، دیتابیس های رابطهای برای مقیاس گذاری مناسب نیستند پس از دیتابیس های غیر رابطهای استفاده کنیم.
هرچند این سیستمهای غیر رابطهای ممکن است برای مقیاس گذاری مناسب باشند اما معایبی هم دارند: قابلیت اطمینان پایین، ضعف در اجرای کوئری، مشکلات سازگاری.
حالا بیایید ببینیم منظور از scalability چیست؟
وقتی صحبت از مقیاس پذیری میشود میدانیم که توسعه دهندگان معمولا به دنبال ترکیبی از 3 مورد زیر هستند:
- عملکرد بهتر در Insert
- عمکرد بهتر در read
- قابلیت دسترسی بهتر (که عمدتا به مقیاس پذیری ربطی نداشته ولی باز هم یکی از دلایل به شمار میآید)
PostgreSQL از 2 ویژگی بالا یعنی عملکرد بهتر در read و قابلیت دسترسی بهتر با استفاده از یک ویژگی به نام همانندسازی جریان (streaming replication) استفاده میکند.
بنابراین اگر workload شما زیر 50 هزار insert در ثانیه است نباید مشکلی با مقایس پذیری از طریق PostgreSQL داشته باشید.
در این مطلب ما در مورد مقیاس پذیری و قابلیت دسترسی در PostgreSQL با استفاده از همانندسازی جریان توضیح میدهیم.
نحوه کار همانندسازی جریانی در PostgreSQL
در سطح بالا همانند سازی جریانی با پخش سوابق تغییرات پایگاه داده از سرور اصلی به یک یا چند سرور رپلیکیشن عمل میکند، که میتواند به عنوان گرههای فقط خواندنی یا به عنوان پیغام عدم موفقیت استفاده شود.
همانندسازی با انتقال مداوم بخشهای WAL از سرور اصلی به هر رپلیکیشن مرتبط کار میکند.
WAL چیست؟
قبل از آنکه بیشتر به replication بپردازیم، ببینیم منظور از WAL چیست؟
WAL(write ahead along) یک سری دستورالعمل است که از هر تغییر کوچک در دیتابیس باخبر میشود.
استفاده کردن از WAL در دیتابیس، یک روش متداول در سیستمهای پایگاه داده برای اطمینان از atomicity و تداوم است. به خصوص تداوم اهمیت بسیار دارد؛ با این تصور که وقتی دیتابیس یک transaction انجام میدهد، داده ی حاصل شده در آینده قابل جستجو است، حتی زمانی که سرور اصطلاحا crash میشود. اینجا ست که WAL وارد عمل میشود.
وقتی یک کوئری را اجرا میکنیم که داده ها را تغییر میدهد (یا تغییرات شمایی ایجاد میکند)، PostgreSQL ابتدا تغییرات را در حافظه ثبت میکند تا بتواند تغییرات را سریع ضبط کند. دسترسی به حافظه بسیار سریع اما بی ثبات است به این معنی که اگر سرور crash شود تغییرات اخیر داده های ما پس از راه اندازی مجدد سرور ناپدید میشوند. بنابراین ما باید نهایتا تغییرات را در یک حافظه ماندگار ذخیره کنیم.هرچند PostgreSQL قبل از ذخیره داده اصلی بر روی دیسک، ابتدا ورودی WAL را ذخیره میکند.
حال این سوال مطرح میشود که چرا از یک ساختار جداگانه استفاده کنیم و مستقیما بر روی یک فایل های اصلی ننویسیم؟ پاسخ در تفاوت سرعت بین نوشتن داده به صورت پیاپی و به صورت تصادفی است. نوشتن بر روی مسیر داده اصلی میتواند بر روی چندین فایل و ایندکس پخش شود، که باعث پرش دیسک میشود. از طرف دیگر، نوشتن بر روی WAL به صورت پی در پی است که همیشه سریع تر است.
حال اگر سرور خراب شود بعد از ری استارت میتواند تمامی تغییرات را بر روی WAL اعمال کند.
در حین یک عملیات عادی PostgreSQL باعث تغییر در حالت پرس و جو میشود و همزمان آنها را بر روی WAL مینویسد. اگر سرور کرش کند، سرور از WAL کمک گرفته و هر تغییری را که میتوانست به خاطر کرش سرور از بین برود را برمیگرداند.
به بیان دیگر WAL یک ریکورد از تمامی مقادیر و متغیرات پایگاه داده است، به طوری که ما میتوانیم تمامی تغییراتی که در حافظه به وجود آمده است اما به خاطر خرابی سرور هنوز به دایرکتوری اصلی داده ها نوشته نشده است را دوباره بازیابی کنیم.
WAL و Replication
متوجه شدیم که WAL در صورتی خرابی و ری استارت شدن سرور به کار می آید اما یک محدودیت بزرگ هم دارد: در صورتی که دیسک خراب شود یا مشکل غیرقابل بازگشت دیگری به وجود آید WAL نمیتواند به ما کمک کند.
فرض کنید که تمام دیتای ما بر روی یک سرور است و به خاطر خرابی برای دیسک ممکن است از بین برود، بنابراین ما به چیزی نیاز داریم که ما را در مقابل خرابی های این چنینی مقاوم کند. اینجا است که replication به کمک می آید.
در اینجا PostgreSQL از یک رویکرد زیرکانه استفاده میکند، به جای آن که از یک ساختار کاملن جدا بسازد که از replication استفاده کند، از WAL به عنوان یک ابزار استفاده کرده و آن را برای بقیه سرورها میفرستد، حالا ما یک رپلیکیشن کامل از دیتابیس خود بر روی یک سرور دیگر داریم!
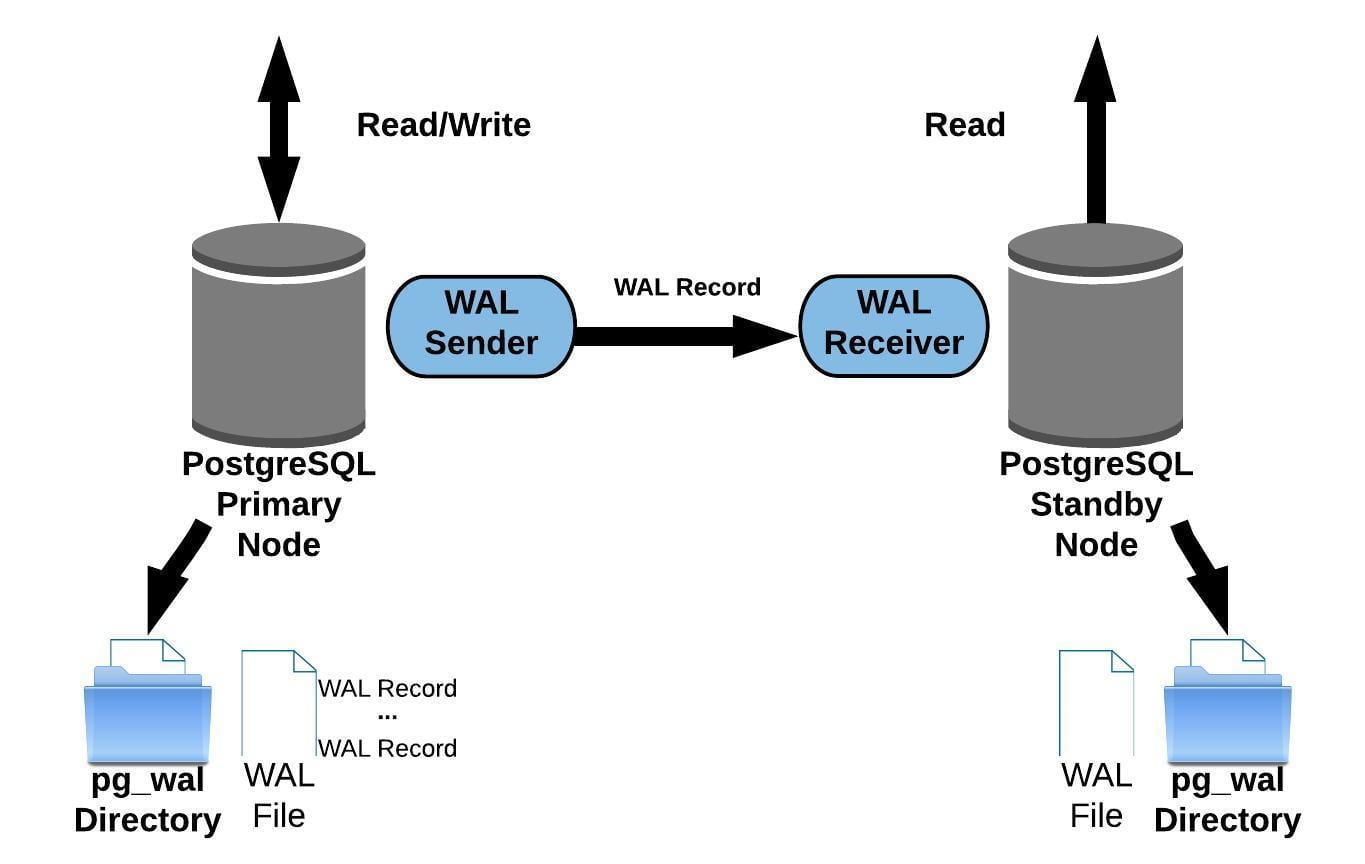
در تصویر بالا میبینیم که سرور اصلی در هر دو حالت read/write تمامی تغییرات داده را کنترل میکند (insert, update,delete) ، برای تمامی transaction ها برنامه ریزی میکند و محل ذخیره، آپدیت، پاک کردن اطلاعات را مشخص میکند،. هرگونه دستورالعمل حاصل از تغییر دیتابیس به WAL ارسال میشود و در این میان یک پیام به مشتری نیز ارسال میشود.
در حالت عادی وقتی در recovery mode قرار داریم، نوشتن و خواندن بر روی دیتابیس مجاز نیست، و یک سرور رپلیکیشن را میتواند بر روی حالت hot standby قرار دهد. این حالت اجازه write را گرفته و شما در وضعیت read-only قرار میگیرید. در نتیجه میتوانید در حالی که تغییرات دیتا در حال استریم شدن است از سرور رپلیکیشن برای خواندن استفاده کنید.
حالات مختلف رپلیکیشن برای موقعیت های مختلف
PostgreSQL از 3 نود اصلی در رپلیکیشن استفاده میکند، که هرکدام از آن ها مقادیر تکرار داده را که قبل از اینکه یک write رخ بدهد اعمال میکند.
Asynchronous replication بعد از اینکه دیتا بر روی WAL اصلی نوشته شد آن را به کلاینت بر میگرداند، اما
Synchronous Write زمانی که برروی WAL نوشته شد این مقدار را برمیگرداند
Asynchronous replication(همانندسازی آسنکرون)
این نوع رپلیکیشن تضمینی در رابطه با اینکه اطلاعات به رپلیکیشن های مختلف ارسال شده یا نه، ندارد.
دیتا زمانی که بر روی WAL سرور اصلی نوشته شد، نوشته شده در نظر گرفته میشود. فرستنده WAL تمام دیتای WAL را بر روی رپلیکیشن های متصل شده پیاده میکند اما این اتفاق به صورت asynchronous و بعد از اینکه WAL نوشته شد می افتد.
Write performance (عملیات نوشتن):
رپلیکیشن به صورت async معروف ترین نوع برای انجام insert ها است. کلاینت ها فقط بایستی منتظر سرور اصلی برای نوشتن WAL باشند. هرگونه تاخیر بین سرور اصلی و سرور رپلیکیشن از مدت زمان نوشتن که مشتری آن را میبیند جدا است.
Read consistency (عملیات خواندن):
از آنجایی که تضمینی وجود ندارد که داده ها پس از نوشتن به صورت موفقیت آمیز به رپلیکیشن منتقل شوند، این حالت ممکن است منجر به ناسازگاری موقت داده ها بین سرور اصلی و سرور رپلیکیشن شود.
تا زمانی که WAL مربوطه به رپلیکیشن نپیوندد و به دیتابیس آن اعمال نشود، مشتریانی که از این رپلیکیشن ها میخوانند، اطلاعات جدید را در کوئری خود نخواهند دید.
Data loss (از دست رفتن دیتا):
از دست دادن داده در این نوع رپلیکیشن اگر که سرور اصلی قبل از رسیدن WAL به سرور رپلیکیشن دچار خرابی شود یک احتمال به شمار میرود. هرچند که اگر سرور اصلی دچار کرش شود و دوباره شروع به کار کند، سرور رپلیکیشن از جایی که داده ها به خاطر خرابی متوقف شده بود دوباره ادامه به کار میدهد.
Synchronous write replication:
این نوع رپلیکیشن تضمین میکند که تمامی مقادیر مشخص شده برای رپلیکیشن، داده ی خود را قبل از اینکه سرور اصلی به مشتری اعلام موفقیت کند بر روی WAL مینویسند.
Write performance (عملیات نوشتن):
عملکرد write در این نوع رپلیکیشن حرکت کندتری نسبت به asynchronous دارد.
Data Loss (از دست رفتن دیتا):
از دست دادن دیتا در این حالت هنوز امکان پذیر است هرچند که نسبت به اجرای async کم تر شده است، در اکثر موارد synchronous هر دو سرور هم اصلی و هم رپلیکیشن دچار کرش میشوند.
Synchronous apply replication:
نه تنها تضمین میکند که WAL برای همه رپلیکیشن ها به صورت مشخص نوشته شده است بلکه تمام بخش های WAL در پایگاه داده اعمال میشوند.
Write performance (عملیات نوشتن):
از آنجایی که مشتری باید منتظر بماند تا کلیه عملیات نوشتن در سرور اصلی و رپلیکیشن انجام شود، این حالت کندترین نوع ممکن است.
Read performance (عملیات خواندن):
تضمین میکند که هر رپلیکیشن مشخص شده به طور کامل با سرور اصلی سازگار باشد و عملیات write تاز مانی که در پایگاه داده اعمال نشود موفقیت آمیز تلقی نخواهد شد.
Data loss (از دست رفتن دیتا):
در مورد از دست دادن دیتا، این نوع از رپلیکیشن حتی تضمین بهتری نسبت به 2 مورد قبلی است.
در هر نوع تنظیماتی از synchronous apply، پایگاه داده اصلی و تمامی رپلیکیشن ها به صورت پایدار خواهند بود.











توضیحات مفیدی بود