
پایگاه داده سند گرا یا Document-Oriented چیست و چه مزایایی دارد؟
پایگاه داده ها نقش بسیار مهمی را در سازمان ها و موسسه های مختلف ایفا می کنند. با اینکه زمان زیادی از معرفی آن ها نگذشته است، اما می توان ردپای پایگاه داده های مبتنی بر کامپیوتر را در همه جا مشاهده کرد. از همه بیشتر، وب سایت ها و اپلیکیشن ها به منظور جمع آوری داده ها، ذخیره و بازیابی اطلاعات از انواع پایگاه داده ها بهره می برند. یکی از پایگاه داده هایی که مزایای بسیار زیاد و منحصر به فردی را به همراه دارد، پایگاه داده سند گرا یا Document-Oriented است. ما در این مطلب قصد داریم تا در خصوص مزایا و نحوه استفاده از چنین پایگاه داده ای با مثال، بیشتر صحبت کنیم.
پایگاه داده NoSQL
برای سالیان سال، مفهوم پایگاه داده تحت سلطه پایگاه داده های اطلاعاتی بود. این مدل از پایگاه داده ها، داده ها را در جداول تشکیل شده از ردیف های مختلف، سازماندهی می کردند. اما وجود معایبی در آن ها، متخصصین را واداشت تا به نوع جدیدی از پایگاه داده ها دست پیدا کنند. از این رو برای رهایی از ساختارهای سفت و سخت تحمیل شده از سوی پایگاه داده های رابطه ای، نوع جدیدی از انواع مختلف پایگاه داده در سال های اخیر، ظهور کرد.
یکی از این مدل پایگاه داده ها، پایگاه داده NoSQL است. دلیل چنین نامگذاری نیز آن است که چنین دیتابیس هایی معمولا از کوئری ساخت یافته یا SQL استفاده نمی کنند. این در حالی است که چنین جست و جوهایی بیشتر در پایگاه داده های رابطه ای برای مدیریت و جستجوی داده ها، مورد استفاده قرار می گرفت. پایگاه داده NoSQL می تواند سطح بالایی از مقیاس پذیری و انعطاف پذیری را از نظر ساختار داده، ارائه دهد.
از این رو چنین پایگاه داده هایی برای مدیریت حجم زیادی از داده ها، سریع تر و چابک تر خواهند بود. نوع جدیدی از پایگاه داده های NoSQL، پایگاه داده سند گرا است. اما آیا می دانید که منظور از پایگاه داده سند گرا چیست؟
پایگاه داده سند گرا چیست؟
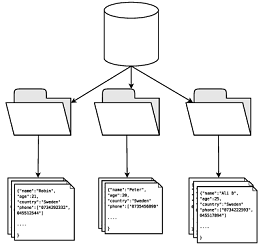
برخلاف پایگاه داده های اطلاعاتی مانند پایگاه داده رابطه ای که متشکل از ردیف ها و ستون های مختلف هستند، پایگاه داده سند گرا، داده ها را به عنوان اسناد و سندهای گوناگون، ذخیره می کند. شما ممکن است یک سند را به عنوان یک ورودی داده مستقل در نظر بگیرید که می تواند شامل تمام آن چیزهایی باشد که برای درک معنای آن لازم است. این سندها، شباهت بسیار زیادی به اسناد مورد استفاده در دنیای واقعی دارند.
یک نمونه از پایگاه داده سند گرا، پایگاه داده Mongo DB است. در زیر نمونه ای از سندی که در چنین پایگاه داده ای ظاهر می شود، آورده شده است. این مثال، نمونه کارت تماس شرکت را نشان می دهد که یک کامند با نام “sammy” را توصیف می کند:
{
"_id": "sammyshark",
"firstName": "Sammy",
"lastName": "Shark",
"email": "sammy.shark@digitalocean.com",
"department": "Finance"
}باید توجه داشته باشید که این سند، به عنوان یک شی JSON نوشته شده است. JSON در واقع یک فرمت داده قابل خواندن برای انسان بوده که در سال های اخیر، محبوبیت زیادی را به دست آورده است. در حالی که بسیاری از فرمت های مختلف را می توان برای نمایش دادن داده ها در یک پایگاه داده سند گرا استفاده کرد، مانند XML یا YAML، اما JSON یکی از رایج ترین و کاربردی ترین آن ها است. برای مثال، پایگاه داده MongoDB، جیسون را به عنوان فرمت داده اولیه برای تعریف و مدیریت داده ها، اتخاذ می کند.
تمامی داده ها در اسناد JSON به صورت جفت فیلدها و مقدار نمایش داده می شوند. شکل آن هم به صورت “فیلد: مقدار” (field: value) است. در مثال بالا، خط اول فیلد با مقدار sammyshark نمایش داده شده است. این مثال همچنین شامل فیلدهایی برای نام، نام خانوادگی، آدرس ایمیل و همچنین بخش هایی است که کارمند در آن جا مشغول به کار است.
نام فیلدها به شما این امکان را می دهد تا متوجه شوید که چه نوع داده ای را در سند نگهداری می کنید. اسناد موجود در پایگاه داده سند گرا، قادر به توصیف خود هستند. به بیان دیگر، هم مقادیر داده ها و هم اطلاعات مربوط به آن ها، قابلیت ذخیره سازی در چنین پایگاه داده ای را دارد. هنگام بازیابی یک سند از پایگاه داده سند گرا، شما همواره می توانید تصویر کاملی از داده را دریافت کنید.
نمونه ای دیگر در پایگاه داده سند گرا
در این قسمت، نمونه دیگری از پایگاه داده سند گرا را به شما نمایش داده ایم. در این مثال یک سند وجود دارد که به همکار “sammy”، یعنی “Tom” اشاره می کند. فردی که در بخش های مختلفی مشغول به کار بوده و دارای نام میانی است:
{
"_id": "tomjohnson",
"firstName": "Tom",
"middleName": "William",
"lastName": "Johnson",
"email": "tom.johnson@digitalocean.com",
"department": ["Finance", "Accounting"]
}این سند، تفاوت هایی با سند موجود در مثال اول دارد. برای نمونه، یک فیلد جدید به نام MiddleName به آن اضافه شده است. همچنین بخش دپارتمان این سند یک مقدار واحد را ذخیره نمی کند؛ بلکه آرایه ای از دو مقدار مختلف را در خود نگهداری خواهد کرد. این دو مقدار عبارت اند از: “Finance” و “Accounting“.
از آن جایی که این اسناد دارای زمینه های متفاوتی از داده ها هستند، می توان گفت که طرحواره های (schemas) متفاوتی نیز دارند. طرحواره پایگاه داده، ساختار رسمی آن است که مشخص می کند چه نوع داده هایی را می توان در آن ذخیره کرد. در مورد پایگاه داده سند گرا باید اشاره کرد طرحواره های آن ها در نام فیلدها و نوع ارزش هایی که آن فیلدها نشان می دهند، انعکاس خواهد یافت.
در یک پایگاه داده رابطه ای، نمی توانید هر دو این نمونه کارت ها را که در مثال های قبل به آن اشاره کردیم، در یک جدول ذخیره کنید. چرا که ساختار آن ها با یکدیگر متفاوت است. شما باید طرحواره پایگاه داده را تطبیق داده تا امکان ذخیره دپارتمان های متعدد و همچنین نام میانی را برای کاربران فراهم کند. از سوی دیگر، لازم است تا یک نام میانی برای فردی مانند “سامی” ارائه دهید. در غیر این صورت، ستون آن با مقدار NULL پر خواهد شد.
اما این مورد در پایگاه داده سند گرا صدق نمی کند. چنین پایگاه داده ای به شما این امکان را می دهد تا اسناد متعدد را با طرحواره های مختلف بدون نیاز به هیچگونه تغییری ذخیره کنید. در یک پایگاه داده سند گرا، اسناد نه تنها خود را توصیف می کنند، بلکه طرحواره آن ها نیز حالتی پویا دارد. این بدان معنی است که دیگری نیازی نیست تا قبل از ذخیره داده ها، آن ها را توصیف کنید. فیلدها می توانند بین اسناد مختلف در یک پایگاه داده، متفاوت باشند. شما می توانید ساختار سند را به میل خود تغییر داده، فیلدهایی را به آن اضافه و یا از آن حذف کنید.
اسناد همچنین می توانند به صورت تو در تو باشند. به این معنی که یک فیلد در یک سند، می تواند خود حاوی یک سند دیگر باشد. از این رو پایگاه داده سند گرا، امکان ذخیره داده های پیچیده را برای شما فراهم خواهد کرد.
مثالی از اسناد تو در تو در پایگاه داده سند گرا
بیایید تصور کنیم که کارت تماس، باید اطلاعات مربوط به حساب های رسانه اجتماعی ای که توسط کارمند استفاده می شود را ذخیره کند. بدین صورت سند شما، به یک سند تو در تو تبدیل خواهد شد:
{
"_id": "tomjohnson",
"firstName": "Tom",
"middleName": "William",
"lastName": "Johnson",
"email": "tom.johnson@digitalocean.com",
"department": ["Finance", "Accounting"],
"socialMediaAccounts": [
{
"type": "facebook",
"username": "tom_william_johnson_23"
},
{
"type": "twitter",
"username": "@tomwilliamjohnson23"
}
]
}در این مثال جدید، فیلدی به نام socialMediaAccounts در سند ظاهر خواهد شد؛ اما به جای یک مقدار واحد، حاوی آرایه ای از اشیا تو در تو است که حساب های رسانه های اجتماعی یک کارمند را توصیف می کند. هر یک از این حساب ها می توانند به تنهایی یک سند باشند. اما در این جا مستقیما در کارت تماس ذحیره شده اند. بار دیگر باید اشاره کرد که نیازی به تغییر ساختار پایگاه داده برای تطبیق در چنین مواردی وجود ندارد. پایگاه داده سند گرا به شما این اجازه را می دهد تا یک سند جدید به مانند سند بالا را ذخیره کنید.
نکته: مرسوم است که در MongoDB فیلدها و مجموعه ها را با استفاده از علامت camelCase نامگذاری کنید. از این رو بین کلمات نباید فاصله باشد. اولین کلمه باید با حروف کوچک نوشته شده و هر کلمه اضافی که بعد از آن حضور دارد، با حروف اول بزرگ ظاهر می شود. باید اشاره داشت که شما همچنین می توانید از نمادهای مختلفی مانند snake_case نیز استفاده کنید. در این حالت، کلمات همه با حروف کوچک نوشته می شوند و با یک آندرلاین (_) از یکدیگر جدا می گردند. در صورتی که در یک پایگاه داده از هر کدام از این نمادها استفاده کردید، باید به طور کامل در کل پایگاه داده به آن پایبند باشید.
مزایای پایگاه داده سند گرا
با این که شاید انتخاب یک پایگاه داده سند گرا در تمامی موارد کار درستی نباشد، اما مزایای این پایگاه داده به قدری زیاد بوده که بسیاری از افراد علاقه مند به کار با آن شده اند. برخی از مهمترین این مزایا عبارت اند از:
- انعطاف پذیری و سازگاری
پایگاه داده های اسنادی دارای سطح بالایی از کنترل بر ساختار داده ها هستند. از این رو امکان آزمایش و انطابق با الزامات جدید را به ساده ترین شکل ممکن، فراهم می کنند. فیلدهای جدید را می توان بلافاصله به پایگاه داده اضافه کرد و همچنین امکان تغییر موارد موجود در هر زمان وجود دارد. همین امر دست توسعه دهنده را به صورت کامل باز خواهد گذاشت.
- توانایی مدیریت داده های ساختار یافته و بدون ساختار
همانطور که پیش از این نیز اشاره شد، پایگاه داده های رابطه ای برای ذخیره سای داده هایی که دارای یک ساختار سفت و سخت هستند، بسیار مناسب خواهد بود. از پایگاه داده سند گرا بیشتر برای ذخیره سازی داده های بدون ساختار استفاده می کنند. اما این بدان معنی نیست که این پایگاه داده نمی تواند برای داده های ساختاریافته نیز مورد استفاده قرار گیرد!
در واقع داده های ساختار یافته اطلاعاتی هستند که به سادگی امکان نمایش آن ها در ردیف ها و ستون ها وجود دارد. در حالی که داده های بدون ساختار عبارتند از پست های رسانه های اجتماعی با متون چند رسانه ای تولید شده توسط انسان یا گزارش های سرور که از یک قالب یکپارچه پیروی نمی کنند.
- مقیاس پذیری بر اساس طراحی
پایگاه های داده رابطه ای اغلب محدود به نوشتن بوده و افزایش عملکرد آن ها مستلزم مقیاس بندی عموی است. به بیان دیگر، باید داده های آن ها را به سرورهای پایگاه داده قدرتمندتر و کارآمدتر منتقل کنید. برعکس، پایگاه داده سند گرا، به عنوان سیستم های توزیع شده ای طراحی شده اند که به شما این امکان را می دهند به صورت افقی نیز آن ها را مقیاس بندی کنید. به این معنی که پایگاه داده واحد را در چندین سرور تقسیم کنید. از آن جایی که اسناد واحدهای مستقلی هستند که هم داده ها و هم طرحواره را شامل می شوند، توزیع آن ها در سرور، تقریبا بی اهمیت است. این امر باعث می شود تا حجم زیادی از داده ها با پیچیدگی عملیاتی کمتر، ذخیره شوند.
- گروه بندی اسناد به مجموعه ها
در حالی که پایگاه داده سند گرا انعطاف پذیری زیادی را در نحوه ساختار اسناد ایجاد می کند، اما داشتن ابزاری برای سازمان دهی داده ها در دسته هایی با ویژگی های مشابه، از سالم بودن و مدیریت شدن پایگاه داده، حمایت می کند. در یک پایگاه داده سند گرا، چندین مجموعه وجود دارد که به مانند کشو یک کابینت عمل می کند. البته این مجموعه، از نظر منطقی شبیه به جداول در پایگاه داده رابطه ای است. نقش یک مجموعه این است که اسنادی را که در دارای عملکرد مشابهی هستند، در کنار هم قرار دهد. حتی اگر اسناد تکی ممکن است در طرحواره خود کمی متفاوت باشند.
داشتن ویژگی های مشابه بین اسناد، در یک مجموعه، همچنین به شما این امکان را می دهد تا نمایه هایی بسازید که امکان بازیابی کارآمدتر اسناد بر اساس جستجوهای مربوط به زمینه های خاص را فراهم می کند.










دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.