 https://getpancake.com/fa/wp-content/uploads/2023/07/MySQL-Cluster.jpg
506
900
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2023-07-20 11:53:452023-07-20 11:53:48MySQL Cluster چیست و دقیقا چه عملی را انجام می دهد؟
https://getpancake.com/fa/wp-content/uploads/2023/07/MySQL-Cluster.jpg
506
900
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2023-07-20 11:53:452023-07-20 11:53:48MySQL Cluster چیست و دقیقا چه عملی را انجام می دهد؟ https://getpancake.com/fa/wp-content/uploads/2023/04/MySQL-Changing-Password.jpg
506
900
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2023-04-21 08:45:002023-04-25 09:05:50نحوه تغییر پسورد کاربر در MySQL به همراه مثال
https://getpancake.com/fa/wp-content/uploads/2023/04/MySQL-Changing-Password.jpg
506
900
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2023-04-21 08:45:002023-04-25 09:05:50نحوه تغییر پسورد کاربر در MySQL به همراه مثال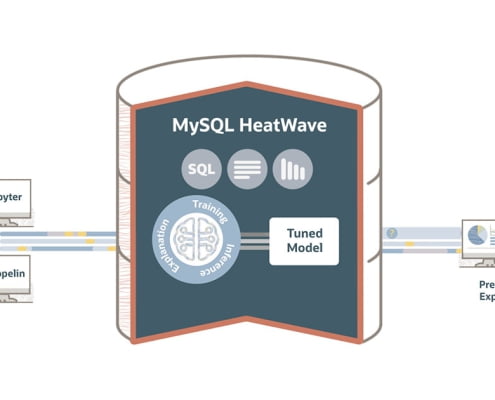 https://getpancake.com/fa/wp-content/uploads/2022/09/og-social-mysql-heatwave.jpg
630
1200
Site Author
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
Site Author2022-09-04 07:05:232022-09-04 07:05:28آشنایی با MySQL HeatWave به زبان ساده
https://getpancake.com/fa/wp-content/uploads/2022/09/og-social-mysql-heatwave.jpg
630
1200
Site Author
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
Site Author2022-09-04 07:05:232022-09-04 07:05:28آشنایی با MySQL HeatWave به زبان ساده https://getpancake.com/fa/wp-content/uploads/2022/08/mysql-create-database.png
506
900
Site Author
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
Site Author2022-08-10 08:26:402022-09-13 05:22:40نحوه ساخت و ایجاد اولین دیتابیس در MySQL
https://getpancake.com/fa/wp-content/uploads/2022/08/mysql-create-database.png
506
900
Site Author
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
Site Author2022-08-10 08:26:402022-09-13 05:22:40نحوه ساخت و ایجاد اولین دیتابیس در MySQL https://getpancake.com/fa/wp-content/uploads/2022/08/1.jpg
600
800
Site Author
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
Site Author2022-08-03 10:46:332022-08-03 10:46:40آموزش گام به گام نصب MySQL روی ویندوز با استفاده از MySQL Installer
https://getpancake.com/fa/wp-content/uploads/2022/08/1.jpg
600
800
Site Author
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
Site Author2022-08-03 10:46:332022-08-03 10:46:40آموزش گام به گام نصب MySQL روی ویندوز با استفاده از MySQL Installer https://getpancake.com/fa/wp-content/uploads/2022/02/MySQL_Replication_and_HA_pancake_dbaas.png
598
1000
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2022-02-24 12:01:282022-07-05 06:02:45دسترسی پذیری بالا برای MySQL و MariaDB: مقایسه رپلیکیشن مستر-مستر با گالرا کلاستر
https://getpancake.com/fa/wp-content/uploads/2022/02/MySQL_Replication_and_HA_pancake_dbaas.png
598
1000
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2022-02-24 12:01:282022-07-05 06:02:45دسترسی پذیری بالا برای MySQL و MariaDB: مقایسه رپلیکیشن مستر-مستر با گالرا کلاستر https://getpancake.com/fa/wp-content/uploads/2021/12/database-backup-plans.jpg
600
1259
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2021-12-16 06:57:462022-07-17 08:24:03آموزش بکاپ گیری از دیتابیس MySQL
https://getpancake.com/fa/wp-content/uploads/2021/12/database-backup-plans.jpg
600
1259
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2021-12-16 06:57:462022-07-17 08:24:03آموزش بکاپ گیری از دیتابیس MySQL https://getpancake.com/fa/wp-content/uploads/2021/02/database-management-3.jpg
627
1200
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2021-02-20 12:47:222022-07-17 08:01:57چگونه دیتابیس خود را مدیریت کنیم؟
https://getpancake.com/fa/wp-content/uploads/2021/02/database-management-3.jpg
627
1200
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2021-02-20 12:47:222022-07-17 08:01:57چگونه دیتابیس خود را مدیریت کنیم؟ https://getpancake.com/fa/wp-content/uploads/2021/02/head-clouds-examining-dbaas-promise.jpeg
469
1080
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2021-02-07 09:42:152022-09-13 05:16:44سرویس پایگاه داده چیست؟
https://getpancake.com/fa/wp-content/uploads/2021/02/head-clouds-examining-dbaas-promise.jpeg
469
1080
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2021-02-07 09:42:152022-09-13 05:16:44سرویس پایگاه داده چیست؟ https://getpancake.com/fa/wp-content/uploads/2021/01/database_features.png
438
748
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2021-01-30 11:26:362022-07-17 09:21:13پنج ویژگی کلیدی که باید هنگام خرید DBaaS در نظر بگیرید
https://getpancake.com/fa/wp-content/uploads/2021/01/database_features.png
438
748
پنکیک
https://getpancake.com/fa/wp-content/uploads/2019/11/pancake-logo.png
پنکیک2021-01-30 11:26:362022-07-17 09:21:13پنج ویژگی کلیدی که باید هنگام خرید DBaaS در نظر بگیرید