چرا سرعت جستجو در الستیک سرچ بیشتر است؟
Elasticsearch یا الستیک سرچ را می توان یک موتور جستجو اوپن سورس معرفی کرد. اگر شما قصد داشته باشید تا کلان داده های خود را جستجو کنید، الستیک سرچ می تواند کمک فراوانی به شما کند. با این وجود گاهی به دلیل نوع ماهیت الستیک، به نظر می رسد که Elasticsearch با پایگاه داده در تضاد است. باید اشاره کرد که سرعت جستجو الستیک سرچ بسیار بالا بوده و به دلیل در دسترس بودن آن، محبوبیت بالایی کسب کرده است. اما واقعا چرا سرعت جستجو در الستیک سرچ بیشتر است؟
آشنایی با الستیک سرچ
پیش از اینکه در خصوص دلایل بالا بودن سرعت جستجو در الستیک سرچ صحبت کنیم، اجازه دهید تا این موتور جستجو را بیشتر به شما معرفی کنیم. الستیک سرچ یک موتور جستجو و تجزیه و تحلیل داده ها بوده که به صورت رایگان و متن باز در اختیار کاربران قرار دارد. از این موتور جستجو می توان برای جستجو در انواع داده ها اعم از متنی، عددی، مکانی، ساختاری و یا حتی بدون ساختار نیز استفاده کرد.
Elasticsearch اولین بار در سال 2010 و توسط فردی به نام Elasticsearch N.V به زبان جاوا توسعه یافته است. این موتور جستجو به علت سرعت و مقیاس پذیری بسیار مناسب خود، توانسته تا محبوبیت بسیار زیادی را در بین کاربران بدست بیاورد. شاید شما هم بخواهید بدانید که چرا سرعت جستجو در الستیک سرچ بیشتر است؟ اما قبل از اینکه بخواهیم به این سوال پاسخ دهیم، لازم است که ابتدا یک سری مفاهیم را بدانید تا در پاسخ نهایی، دچار سردرگمی نشوید.
مفاهیمی که باید با آن آشنا شوید
اگر می خواهید بدانید که دلیل سرعت جستجو الستیک سرچ چیست، بدون شک در قدم اول باید با یک سری از مفاهیم آشنایی پیدا کنید. این مفاهیم در درک هرچه بهتر نحوه کار Elasticsearch به شما کمک فراوانی خواهد کرد:
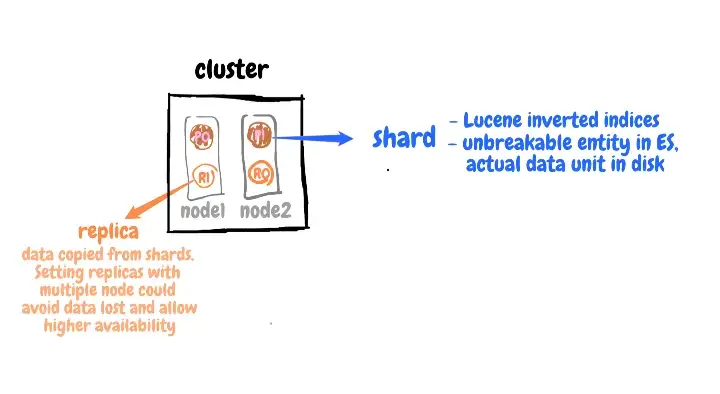
- خوشه (Cluster): هر خوشه یا کلاستر از چندین گره تشکیل شده است.
- گره (Node): به بیان ساده، Node به معنای تعداد فرایندهای الستیک سرچ است. شما این قابلیت را دارید تا بیش از یک فرایند الستیک را فعال کنید. بدین صورت، چندین گره ایجاد کرده اید. هر چند ما معمولا گره های مختلف را در ماشین های مختلفی توسعه می دهیم که این کار باعث دسترس پذیری بیشتر سرویس ها می شود.
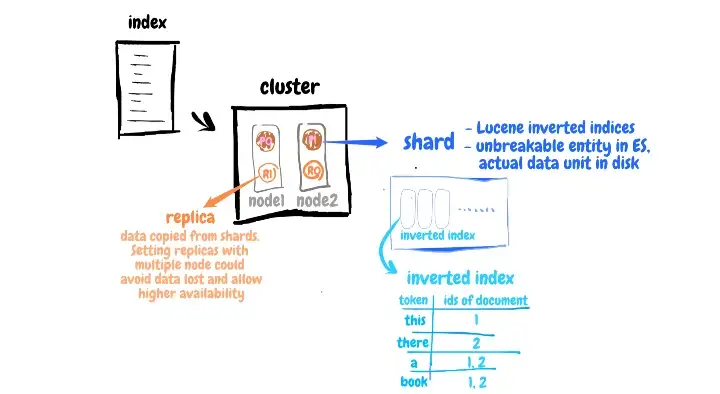
- شارد (Shards): شارد ها کوچکترین واحد داده در دیسک بوده و در واقع کوچکترین موجودیت در الستیک سرچ هستند.
- کپی ها (Replicas): این موارد، داده های کپی شده از شاردها هستند. تنظیم کپی ها با چندین گره می تواند جلوی از دست رفتن داده ها در هنگام به وجود آمدن مشکل در ماشین را گرفته و دسترس پذیری بیشتری را برای کاربر فراهم کند.
ماهیت شارد: مجموعه شاخص های معکوس
برای یک کاربر Elasticsearch کار با عملگرهای CRUD (یا همان Create, Reed, Update, Delete) بسیار ضروری است. در واقع هنوز شاخص، واحد منطقی داده ها است و شاردها بیان کننده موجودیت واقعی داده ها هستند. اما برای درک سرعت جستجو الستیک سرچ باید بدانید که شارد چیست و Elasticsearch چگونه متن ورودی را به شارد ترجمه می کند!
شاردها نگه دارنده اندیس های معکوس هستند و ما به فرایند تبدیل متن ورودی به شاخص معکوس، فرایند ایندکس کردن یا Indexing می گوییم. پس از ایندکس سازی، Elasticsearch چندین جدول شاخص معکوس ایجاد کرده و به همین دلیل، سرعت جستجو در الستیک سرچ بالا می رود.
Indexing: از متن به شاخص های معکوس
بیشتر اوقات، ما یک داده json را به موتور جستجو الستیک سرچ وارد کرده و می توانیم به کمک آن، داده های خود را جستجو کنیم. فرایندی که در این میان انجام می شود و داده ورودی شما را برای Elasticsearch قابل جستجو می سازد، indexing گفته می شود. برای مثال ما عبارتی ماند There is a book را به موتور جستجوی الستیک وارد می کنیم. پس از پست این داده، الستیک سرچ آنالیزهای خود با این متن را آغاز می کند.
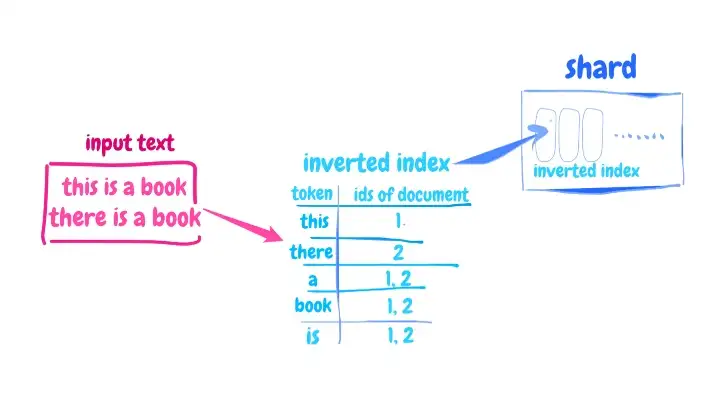
Elasticsearch این تجزیه و تحلیل را بر اساس توکن سازها و فیلترهای خاص شما، انجام خواهد داد. از این رو ممکن است نتیجه تجزیه و تحلیل برای هر جستجویی متفاوت باشد. در این مثال، جمله ای که وارد می کنیم به چندین توکن تقسیم خواهد شد. حال الستیک سرچ جدول شاخص های معکوس را ایجاد می کند. این جدول شامل توکن ها و ID های داکیومنت خواهد بود.
الستیک سرچ همچنین می تواند ابزار بصری Kibana را هم در اختیار ما قرار دهد. از طریق Kibana devtool می توانیم در خواست _analysis api را برای دریافت نتیجه بهتر تجزیه و تحیل، داشته باشیم. کم کم متوجه می شوید که چرا سرعت جستجو در الستیک سرچ بیشتر خواهد بود.
فرایند جستجو: همان آنالیزورها، همان نتایج
بعد از فرایند indexing، الستیک سرچ می تواند داده های ورودی شما را قابل جستجو کند. حال زمان آن رسیده است تا فرایند جستجو آغاز شود. اما فرایند جستجو چگونه در الستیک سرچ اتفاق می افتد؟
اول از همه، الستیک سرچ داده های ورودی شما را مورد تجزیه و تحلیل قرار می دهد. این تجزیه و تحلیل همان فرایندی است که شما به آن فهرست بندی هم می گوید. از آن جایی که فرایند با فرایند قبلی مشابه است، باید از همان تحلیلگر استفاده کنید.
در قدم دوم، الستیک سرچ، در جدول معکوس خود، به دنبال آی دی مشخص شده داکیومنتی که حاوی نتیجه تحلیلگر است خواهد بود. پس از اینکه شناسه اسناد دریافت شد، موتور جستجو الستیک، باید بداند که این اسناد توسط کدام گره ذخیره شده اند. در این بخش، شناسه های موجود با استفاده از تابع هش به شماره گره مورد نظر، ترجمه می شوند.
در آخرین قدم نیز الستیک سرچ، سندی را که جستجو می کنید به سرعت به شما باز می گرداند. در عین حال، تمام داده های مشابه را برای اطمینان از در دسترس بودن، به روز رسانی خواهد کرد. به همین دلیل فرایند جستجو موثر و بهینه شده و سرعت جستجو در الستیک سرچ افزایش پیدا خواهد کرد.



دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.