
مقایسه رپلیکیشن Streaming و Logical در دیتابیس PostgreSQL
پایگاه داده ها سیستم هایی هستند که گاهی به صورت اشتراکی مورد استفاده بخش های مختلف یک شرکت یا سازمان قرار می گیرند. از این رو برای حفظ و نگهداری ایمن اطلاعات از ریپلیکیشن ها استفاده می شود. ریپلیکیشن در واقع روشی به معنای تکثیر و تکرار اطلاعات در پایگاه داده است. بنابراین برای اطمینان بیشتر به اطلاعات ذخیره شده، همیشه یک نسخه پشتیبان از دیتابیس تهیه می شود تا در مواقع لزوم بتوان اطلاعات را بازیابی نمود. رپلیکیشن در PostgreSQL به دو صورت به وجود می آید و هر دو شکل کاربرد خاص خود را دارند. درک نحوه اعمال یک یا هر دو روش تکثیر داده می تواند فرآیندهای توزیع داده شما را ساده کند و از آخرین عملیاتی که روی پایگاه داده انجام داده اید یک پشتیبان تهیه کند تا از دست نروند.
در این مطلب قصد داریم نگاهی به مزایا، معایب و موارد استفاده از استریم تکراری و منطقی در دیتابیس PostgreSQL بیندازیم. با ما همراه باشید شاید پاسخ پرسش شما هم در این مطلب یافت شود.
تعریف تکرار داده ها در PostgreSQL
همانطور که از نام آن پیداست، تکرار، فرآیند کپی مکرر داده ها از یک پایگاه داده در یک سرور کامپیوتر، به پایگاه داده دیگر در یک سرور دیگر است. بنابراین همه کاربران به یک سطح از اطلاعات دسترسی دارند. در محاسبات ابری و سیستم های شبکه، از تکرار برای رفع عیوب یک سیستم دیجیتال استفاده می شود. رپلیکیشن در PostgreSQL از اطلاعات ارزشمند محافظت و توسعه آن ها را ساده می کند.
در PostgreSQL، دو گزینه برای تکرار وجود دارد:
- تکرار منطقی (Logical Replication)
- تکرار جریانی (Streaming Replication)
هر کدام از این روش ها کاربردهای مختلفی دارند و به عنوان یک توسعه دهنده، ممکن است تمایل بیشتری به استفاده از یکی نسبت به دیگری پیدا کنید. اما خوب است بدانید که چگونه از هر دو استفاده کنید تا تجربه کار با هر دو را داشته باشید و برای پروژه های مختلف راحت تر تصمیم بگیرید. در بخش بعدی به شرح و بررسی هر یک از آن ها می پردازیم:
رپلیکیشن منطقی یا Logical در PostgreSQL
تکرار منطقی در PostgreSQL برای نسخه 10.0 معرفی شد. همانندسازی منطقی داده ها در پایگاه داده از طریق کپی یا تکثیر اطلاعات انجام می شود و کاربر می تواند روی نمونه های کپی شده تغییرات دلخواهش را اعمال نماید. در موارد بسیاری داده های اصلی بدون تغییر باقی می مانند و اگر دیتاهای کپی شده دچار مشکل شوند، می توان از روی دیتاهای اصلی مجددا کپی را انجام داد و به این ترتیب دیتاهای جدیدی ایجاد نمود.
رپلیکیشن در PostgreSQL به کاربران کمک می کند کنترل دقیقتری روی داده های تکراری داشته باشند و امنیت داده های اصلی تضمین شود. رپلیکیشن در PostgreSQL در اصطلاح منطقی برای تکثیر داده ها از تکرار بایت به بایت و آدرس های بلوک دیتا استفاده می کند.
این روش طبق یک الگوی خاص برای انتشار و به اشتراک گذاری دیتاهای کپی شده عمل می کند و این امکان را فراهم می کند تا کاربران به صورت گروهی دسته بندی شوند و برای هر گروه می توان دسترسی خاصی تعریف نمود. هر گروه با توجه به سطح دسترسی می تواند بخشی از دیتاهای پایگاه داده را جدا کند و آن ها را حذف، ویرایش یا مجددا پیکربندی کرده و ذخیره نماید.
همانندسازی داده های منطقی می تواند به شکل تکرار تراکنشی نیز باشد. اگر کاربر بخواهد جدولی را کپی کند، میتواند از این روش تکرار برای گرفتن یک کپی فوری از دادهها استفاده کند و آن را به پایگاه داده مشترک ارسال نماید. همانطور که کاربران به صورت گروهی می توانند تغییراتی در داده های اصلی ایجاد کنند، پایگاه داده نیز همزمان به روز رسانی می شود. برای اطمینان از ثبات عملکرد تراکنش ها روی دیتاهای پایگاه داده، باید پس از اعمال تغییرات پایگاه داده را بررسی نمود.
مزایای رپلیکیشن منطقی در PostgreSQL
تکرار منطقی در پایگاه داده مزایای بسیاری دارد که در این قسمت به شرح آنها می پردازیم:
رپلیکیشن لوجیکال کاربران را قادر می سازد تا از یک سرور مقصد برای نوشتن استفاده کنند و به توسعه دهندگان این امکان را می دهد که فهرست ها و تعاریف امنیتی متفاوتی داشته باشند. این امر باعث می شود انعطاف پذیری بیشتری برای انتقال داده ها بین کاربران با هر سطح دسترسی، فراهم شود.
- پشتیبانی از نسخه های مختلف:
یکی از مزایای رپلیکیشن Logical در دیتابیس PostgreSQL این است که از نسخه های مختلف پشتیبانی می کند و می تواند در نسخه های مختلف PostgreSQL پیکربندی شود. همچنین فیلترینگ مبتنی بر رویداد را فراهم می کند. دیتاها میتوانند چندین سری کپی داشته باشند و با هر سطح دسترسی میان کابران شبکه به اشتراک گذاشته شوند.
- حداقل بار سرور:
رپلیکیشن منطقی در پستگرس کیو ال، در مقایسه با سایر روش ها کمترین میزان بار را به سرور وارد می کند و در عین حال انعطاف پذیری ذخیره سازی را از طریق تکرار مجموعه های کوچکتر فراهم می نماید. همانطور که در بالا ذکر شد، همانند سازی داده های منطقی می تواند حتی داده های موجود در جداول پارتیشن بندی شده اصلی را کپی کند. تکرار منطقی، می تواند حتی در زمان راهاندازی اولیه، دادهها را تبدیل کند و امکان پخش موازی بین کاربران را فراهم نماید.
معایب تکرار منطقی در PostgreSQL
این روش نیز دارای معایب بسیاری است که از جمله آن ها می توان به موارد زیر اشاره نمود:
- همانندسازی منطقی توالی ها، اشیاء بزرگ، نماهای مادی شده، جداول ریشه پارتیشن و جداول خارجی را کپی نمی کند.
- در PostgreSQL، تکثیر داده های منطقی تنها توسط عملیات DML پشتیبانی می شود.
- توسعه دهندگان نمی توانند از DDL یا کوتاه کردن استفاده کنند و اسکیما باید از قبل تعریف شود. علاوه بر این، از تکرار متقابل (دو جهته) نیز پشتیبانی نمی کند.
- اگر کاربران با مشکلاتی روی دادههای تکرار شده در جدول مواجه شوند، تکرار متوقف میشود. تنها راه برای از سرگیری رپلیکیشن این است که علت بروز مشکل حل شود. بروز یک مشکل ناخواسته می تواند عملکرد تیم را متوقف کند، بنابراین باید بدانید که چگونه هر مشکلی را به سرعت حل کنید. اگر مشکل به سرعت برطرف نشود، خطای تکثیر به وجود می آید و سیستم شروع به ایجاد گزارشهای Write-Ahead (WAL) میکند و در نهایت فضای دیسک به سرعت پر می شود!
کاربردهای تکرار منطقی در PostgreSQL
بسیاری از مهندسان از رپلیکیشن منطقی در PostgreSQL برای موارد زیر استفاده می کنند:
- توزیع تغییرات در یک پایگاه داده یا زیرمجموعه ای از یک پایگاه داده به مشترکین به صورت Real Time
- ادغام چندین پایگاه داده در یک پایگاه داده مرکزی (اغلب برای استفاده در تجزیه و تحلیل)
- ایجاد تکرار در نسخه های مختلف PostgreSQL
- استقرار تکرار بین نمونه های PostgreSQL در پلتفرم های مختلف، مانند لینوکس به ویندوز
- به اشتراک گذاری داده های تکراری با سایر کاربران یا گروه ها
- توزیع زیر مجموعه پایگاه داده بین چندین پایگاه داده
رپلیکیشن Streaming در PostgreSQL
رپلیکیشن جریانی در PostgreSQL از نسخه PostgreSQL 9.0 به بعد معرفی شد. این فرآیند فایلهای Write-Ahead Logging (WAL) را از یک سرور اصلی دریافت میکند و عملیات تکرار را روی آن اعمال میکند. WAL ها برای تکرار و اطمینان از یکپارچگی داده ها استفاده می شوند.
رپلیکیشن Streaming چگونه کار می کند؟
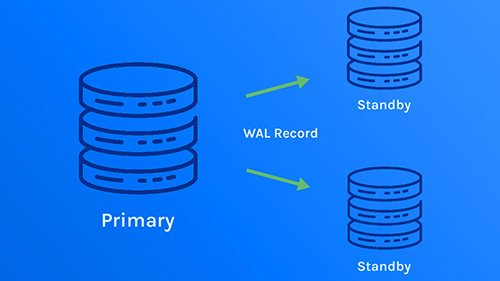
رپلیکیشن استریم، برای پر کردن نواقص بین انتقال دادهها در ارسال گزارش مبتنی بر فایل استفاده می شود و تا زمانیکه WAL به حداکثر ظرفیت برای ارسال داده برسد، ادامه می یاید. با انتشار سوابق WAL، سرورهای پایگاه داده، سوابق WAL را به صورت بخش به بخش برای همگام سازی داده ها، پخش می کنند. سرور به ماکت متصل می شود و بخش های WAL را دریافت می کند. با پخش جریان، کاربر باید تصمیم بگیرد که تکرار (به صورت ناهمزمان یا همزمان) را پیکربندی کند. پخش جریانی در ابتدا به طور پیش فرض به تکرار ناهمزمان تبدیل می شود.
رپلیکیشن جریان در PostgreSQL نشان می دهد بین تغییر اولیه و انعکاس آن تغییر، روی ماکت تاخیر وجود دارد. اگر نسخه اصلی قبل از کپی کردن تغییرات از کار بیفتد یا اگر نسخه مشابه با نسخه اصلی هماهنگ نباشد، احتمال از دست دادن اطلاعات به صورت بالقوه افزایش می یابد.
تکرار همزمان یک گزینه بسیار امنتر است زیرا تغییرات را بلادرنگ ایجاد می کند. در روش تکرار همزمان، انتقال از Master به Replica تا زمانی که هر دو سرور اطلاعات را تأیید کنند، ناقص در نظر گرفته می شود. پس از تایید تغییرات داده ها، انتقال در WAL هر دو سرور ثبت می شود.
چه از تکثیر ناهمزمان استفاده کنید و چه از همزمان، کپی ها باید از طریق اتصال شبکه به Master متصل شوند. علاوه بر این، برای کاربران ضروری است که امتیازات دسترسی را برای جریانهای WAL کپی تنظیم کنند، تا اطلاعات به خطر نیفتد و مشکلی برای آنها پیش نیاید.
مزایای تکرار جریان در PostgreSQL
رپلیکیشن استریمینگ در دیتابیس PostgreSQL مزایای بسیاری دارد که از جمله آن ها می توان به موارد زیر اشاره نمود:
- یکی از مهمترین مزایای استفاده از پخش جریانی این است که صرفا یک راه برای از دست رفتن اطلاعات وجود دارد. تنها راه از دست رفتن داده ها این است که سرورهای اصلی و گیرنده، هر دو همزمان از کار بیفتند! که این امر بسیار غیر معمول است. اگر اطلاعات مهمی را در اختیار شما قرار بدهند، Streaming Replication، تضمین میکند که همواره یک کپی از اطلاعات شما در یک سرور ذخیره میشود.
- کاربران میتوانند بیش از یک سرور آماده به کار را به اصلی متصل کنند و گزارشها از حالت اولیه به هر یک از استندبایهای متصل پخش میشوند. اگر یکی از کپیها به تأخیر بیفتد یا قطع شود، پخش جریانی به نسخههای دیگر ادامه مییابد.
- راهاندازی انتقال گزارش از طریق رپلیکیشن جریانی با هر چیزی که کاربر در حال حاضر در پایگاه داده اصلی اجرا میکند، تداخلی نخواهد داشت. اگر سرور داده اولیه باید خاموش شود، قبل از خاموش شدن منتظر میماند تا رکوردهای بهروزرسانی شده ارسال شوند.
معایب تکرار جریان در PostgreSQL
از جمله معایب رپلیکیشن در PostgreSQL به صورت جریان دیتا، می توان به موارد زیر اشاره نمود:
- تکرار جریانی، اطلاعات را در نسخه یا سیستم دیگری کپی نمیکند، همچنین اطلاعات سرورهای آماده به کار را تغییر نمیدهد و تکثیر دانهای ارائه نمیدهد. بهویژه با تکثیر دادههای جریان ناهمزمان، فایلهای WAL قدیمیتر که هنوز در نسخه کپی نشدهاند، ممکن است زمانی که کاربر تغییراتی در نسخه اصلی ایجاد میکند، بازیافت شوند. برای اطمینان از اینکه فایل های حیاتی از بین نمی روند، کاربر می تواند wal_keep_segments را فعال نماید.
- اگر پیکربندی اعتبار تأیید هویت کاربر برای سرورهای مشابه انجام نشده باشد، استخراج داده های حساس می تواند آسان باشد.
- برای اینکه بهروزرسانیهای بیدرنگ بین Master و Replica انجام شود، کاربر باید روش تکرار را از تکرار ناهمزمان پیشفرض به تکرار همزمان تغییر دهد.
کاربردهای رپلیکیشن استریم در PostgreSQL
بسیاری از مهندسان از رپلیکیشن استریم در PostgreSQL برای موارد زیر استفاده می کنند:
- ایجاد یک نسخه پشتیبان برای پایگاه داده اصلی خود در صورت خرابی سرور یا از دست دادن اطلاعات
- ایجاد راه حلی با قابلیت دسترسی بالا با کمترین تأخیر ممکن
- تخلیه کوئری های بزرگ برای رهایی از فشار روی سیستم اولیه
- توزیع بارهای کاری پایگاه داده در چندین ماشین، به ویژه برای فرمت های فقط خواندنی
نسخه جدید PostgreSQL در بخش رپلیکیشن چه امکاناتی دارد؟
پستگر اس کیو ال نسخه 14 کاربران را قادر می سازد تا کارهای زیر را انجام دهند:
- پارامتر سرور را تنظیم log_recovery_conflict_waits کنند تا زمانهای انتظار طولانی بازیابی را بهطور خودکار گزارش کند.
- توقف بازیابی در سرور آماده به کار هنگام تغییر پارامترها در سرور اصلی (به جای خاموش کردن فوری حالت آماده به کار).
- استفاده از تابع ()pg_get_wal_replay_pause_state برای گزارش وضعیت بازیابی با جزئیات بیشتر.
- با استفاده از in_hot_standby یک پارامتر سرور فقط خواندنی ارائه دهند.
- جداول کوچک را در هنگام بازیابی در خوشه هایی که تعداد زیادی بافر مشترک دارند، به سرعت کوتاه کنند.
- اجازه همگام سازی سیستم فایل در شروع بازیابی خرابی از طریق لینوکس.
- از تابع ()pg_xact_commit_timestamp_origin در یک تراکنش مشخص برای برگرداندن commit.
- استفاده از تابع ()pg_last_committed_xact برای اضافه کردن مبدا تکرار در رکورد برگشتی.
- استفاده از کنترلهای مجوز تابع استاندارد برای تغییر توابع مبدا تکرار
نسخه 14 در رپلیکیشن Logical، کاربران را قادر می سازد تا عملیات زیر را انجام دهند:
- با استفاده از API تکرار منطقی، تراکنش های در حال انجام طولانی مدت را میان چندین سیستم پخش کنند.
- اجازه چندین تراکنش در طول تکرار جدول.
- ایجاد تراکنشهای فرعی WAL-log و انجمنهای XID.
- استفاده از تابع ()pg_create_logical_replication_slot برای تقویت APIهای رمزگشایی منطقی برای تعهدات دو فازی.
- در حین تکمیل فرمان، پیامهای عدم اعتبار کش را به WAL اضافه کنند تا امکان پخش منطقی تراکنشهای در حال انجام فراهم شود.
- کنترل کنند که کدام پیام های رمزگشایی منطقی به جریان تکرار ارسال می شوند.
- از حالت انتقال باینری برای تکرار سریعتر استفاده کنند.
PostgreSQL در حال حاضر روی انتشار نسخه 15 کار می کند و قرار است این نسخه در سه ماهه سوم سال 2022 منتشر شود. یکی از مواردی که در مورد Replication باید در جدیدترین نسخه به آن پرداخته شود، جلوگیری از استفاده از متغیرهای به ارث رسیده از محیط سرور در پخش استریم است. اما همانطور که کاربران بیشتری از نسخه 14 استفاده می کنند، PostgreSQL قابلیت های بیشتری را برای بهبود عملکرد رپلیکیشن اضافه خواهد کرد.
مقایسه سریع رپلیکیشن Logical و Streaming در دیتابیس PostgreSQL
| مدل تکثیر | Logical Replication | Streaming Replication |
| تاخیر در تکرار | تضاد باعث توقف تکرار می شود. | تکرار ناهمزمان ممکن است باعث ایجاد تاخیر میان انتقال اولیه و تکرار شود. در تکرار همزمان داده ها تنها در صورتی از بین می روند که همه سرورهاd متصل به صورت همزمان از کار بیفتند. |
| امکان تکرار در پلفرم های مختلف | بله | خیر |
| امنیت | دسترسی به داده ها محدود به کاربران است. | برای ایمن نگه داشتن داده ها باید اعتبارسنجی یا احراز هویت را پیکربندی نمایید. |
| میزان تکرار | برای تکرار دانه ای گزینه مناسبی است. | برای تکرار در مقیاس بزرگ گزینه مناسب است. |
| کاربرد | ادغام چنیدن سیستم در یک پایگاه داده | ایجاد یک پایگاه داده پشتیبان |
امیدواریم این مطلب به شما هم کمک کرده باشد. در صورت وجود هر گونه سوال، پیشنهاد یا تجربه کار می توانید از طریق درج کامنت یا تماس با ما، با متخصصین ما در پنکیک، در ارتباط باشید.




دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.